LDA(Latent Dirichlet Allocation)是一种文档主题生成模型(generative model),也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。
文档到主题服从多项式分布,主题到词服从多项式分布。Dirichlet Distribution 是多项式分布的共轭先验分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息。
它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序。
每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
对于语料库中的每篇文档,LDA定义了如下生成过程(generative process):
- 按照概率选中一篇文档
- 从Dirichlet分布 中抽样生成文档 的主题分布
- 从主题分布 中抽取文档 第 j 个词的主题
- 从Dirichlet分布 中抽样生成主题 对应的词分布
- 从词分布 中抽样生成词
每一篇文档与 T 个主题的一个多项分布 (multinomial distribution)相对应,将该多项分布记为θ。
每个主题又与词汇表(vocabulary)中的 V 个单词的一个多项分布相对应,将这个多项分布记为φ。
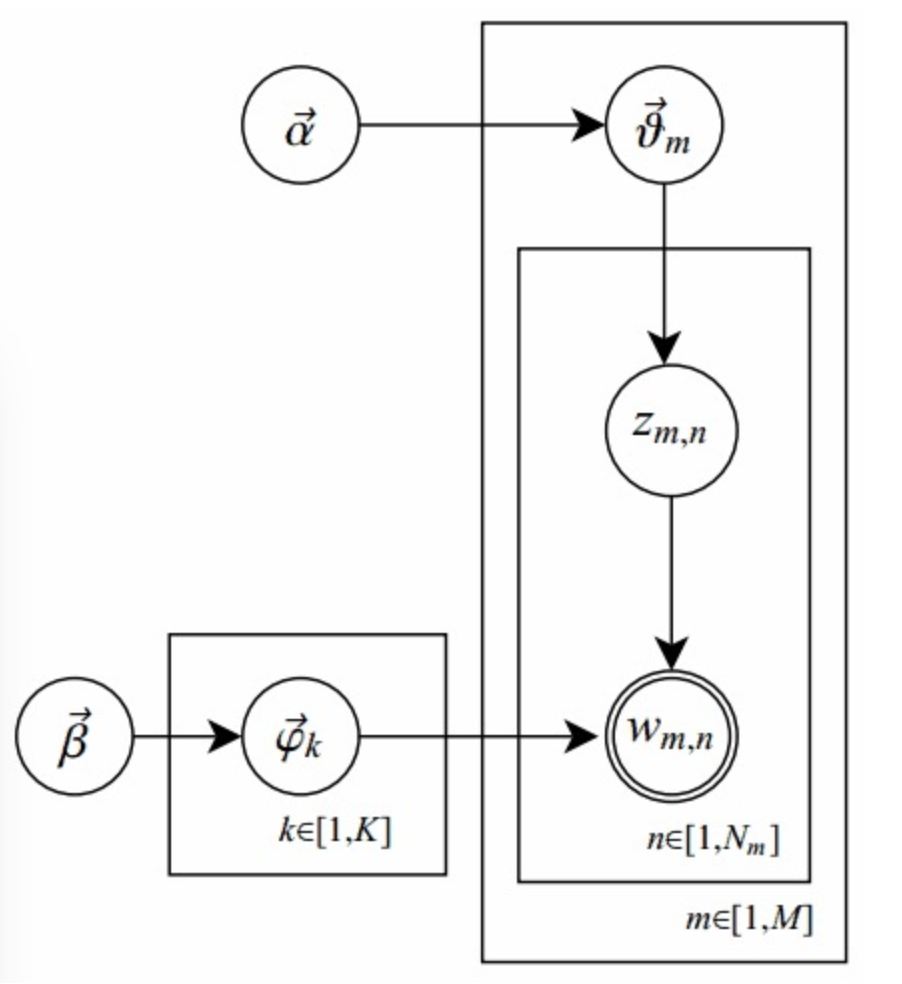
先定义一些字母的含义:
- 文档集合 D
-
主题(topic) 集合 T
-
D 中每个文档 d 看作一个单词序列 <w1, w2, …, wn>,wi 表示第 i 个单词,设 d 有 n 个单词。(LDA 里面称之为word bag,实际上每个单词的出现位置对 LDA 算法无影响)
- D中涉及的所有不同单词组成一个大集合 VOCABULARY(简称 VOC),LDA 以文档集合 D 作为输入,希望训练出的两个结果向量(设聚成 k 个topic,VOC 中共包含 m 个词):
- 对每个 D 中的文档 d,对应到不同 Topic 的概率 ,其中,表示 d 对应 T 中第 i 个 topic 的概率。计算方法是直观的,,其中 表示 d 中对应第 i 个 topic 的词的数目,n 是 d 中所有词的总数。
- 对每个 T 中的 topic t,生成不同单词的概率 ,其中,表示 t 生成 VOC 中第 i 个单词的概率。计算方法同样很直观, ,其中表示对应到 topic t 的 VOC 中第 i 个单词的数目,N 表示所有对应到 topic t 的单词总数。
LDA的核心公式如下:
直观的看这个公式,就是以Topic作为中间层,可以通过当前的 和 给出了文档 d 中出现单词 w 的概率。其中p(t|d)利用 计算得到,p(w|t) 利用 计算得到。
实际上,利用当前的 和 ,我们可以为一个文档中的一个单词计算它对应任意一个 Topic 时的 p(w|d),然后根据这些结果来更新这个词应该对应的 topic。然后,如果这个更新改变了这个单词所对应的 Topic,就会反过来影响 和 。
LDA算法开始时,先随机地给 和 赋值(对所有的 d 和 t )。然后上述过程不断重复,最终收敛到的结果就是LDA的输出。
再详细说一下这个迭代的学习过程:
-
针对一个特定的文档 中的第 i 单词 ,如果令该单词对应的 topic 为 ,可以把上述公式改写为:
-
现在我们可以枚举 T 中的 topic j,得到所有的,其中 j 取值 1~k。然后可以根据这些概率值结果为 中的第 i 个单词 选择一个topic。最简单的想法是取令 最大的 (注意,这个式子里只有j是变量),即
-
然后,如果 中的第 i 个单词 在这里选择了一个与原先不同的topic,就会对 和 有影响了(根据前面提到过的这两个向量的计算公式可以很容易知道)。它们的影响又会反过来影响对上面提到的 p(w|d) 的计算。对D中所有的d中的所有w进行一次 p(w|d) 的计算并重新选择topic 看作一次迭代。这样进行n次循环迭代之后,就会收敛到LDA所需要的结果了。
PLSI 可以依赖 EM 算法得到较好的解决,LDA 的学习属于 Bayesian Inference,只有 MCMC 或者 Variational Inference 可以解决。LDA 原始论文使用的 VI 来解决,但是后续大多数 LDA 相关论文都选择了 MCMC 为主的 Gibbs Sampling 来作为学习算法。
从最高的层次上来理解,VI 是选取一整组简单的、可以优化的变分分布(Variational Distribution)来逼近整个模型的后验概率分布。当然,由于这组分布的选取,有可能会为模型带来不小的误差。不过好处则是这样就把Bayesian Inference的问题转化成了optimization问题。
从 LDA 的角度来讲,就是要为θ以及 z 选取一组等价的分布,只不过更加简单,更不依赖其他的信息。在 VI 进行更新 θ 以及 z 的时候,算法可以根据当前的 θ 以及 z 的最新值,更新 的值(这里的讨论依照原始的 LDA 论文,忽略了β的信息)。整个流程俗称变分最大期望(Variational EM)算法。
Basic Related Math
Gamma Function
这是个函数!不是分布!
Gamma 函数有个很好的递归性质:
可以表述为阶乘在实数集上的延展:
Binomial Distribution
二项分布,伯努利分布(0-1 分布):
Multinomial Distribution
多项式分布:
Beta Distribution
if
Is a normalizing factor
有非常好的Beta-Binomial共轭性质,因为 beta 分布的形式和二项分布的形式相似,由符合 beta 分布的参数先验推出的后验分布也符合 beta 分布(共轭分布的性质)。例如:二项分布的先验分布服从beta 分布 ,已知投了 5 次硬币,3 次 X=1,2 次 X=0,那么新的预测分布更新为
Beta-Binomial 共轭意味着,如果为二项分布的参数θ选取的先验分布是Beta分布,那么以θ为参数的二项分布用贝叶斯估计得到的后验分布P(θ|X)仍然服从Beta分布,那么Beta分布就是二项分布的共轭先验分布
采用共轭先验的原因:
可以使得先验分布和后验分布的形式相同,这样一方面合符人的直观(它们应该是相同形式的)另外一方面是可以形成一个先验链,即现在的后验分布可以作为下一次计算的先验分布,如果形式相同,就可以形成一个链条。
后验概率 ∝ 似然函数*先验概率 即
另外,θ的期望:
Dirichlet Distribution
dirichlet 分布式 Beta 分布的推广:
Dirichlet 分布的期望: