之前使用的表示 word 的方法是 one-hot representation
但是这种方法一个缺陷是维度过高,另外无法表示词语之间的相似性(因为词与词之间的向量正交 orthogonal)
所以想要找到一种方法能够直接 encode 词语之间的 similarity
You shall know a word by the company it keeps. ——J.R. Firth
我们能从一个词周围的信息(neighbor/context)来表示这个词
Loss function:
通过不断的调整词向量的值来减小 loss
Basic Idea of Word2Vec:
Predict between every word and its context words
两个算法:
- Skip-grams (SG): 给定 target word, 预测 context words
- Continuous Bag of Words (CBOW): 从 bag-of-words context 预测 target words
两种训练方法:
- Hierarchical Softmax
- Negative Sampling
- Naive Softmax
Skip-gram
给定 target / center word ,预测以 m 为窗口大小的左侧 context words 和右侧 context words
Loss function / cost function / objective function:给定 current center word, 最大化 context word 的概率
Negative Log Likelihood:
最简单的形式是:
其中:o 是 outside word index,c 是 center word index,和是”center”和”outside” vectors
每个词有两个向量,一个是作为 center word 时的向量,一个是作为 outside word 时的向量,两个向量互相独立
Dot product: ,如果两个向量 u 和 v 越相似,那么点乘的值越大,所以是在计算两个词之间的相似度
softmax:standard map from to a probability distribution
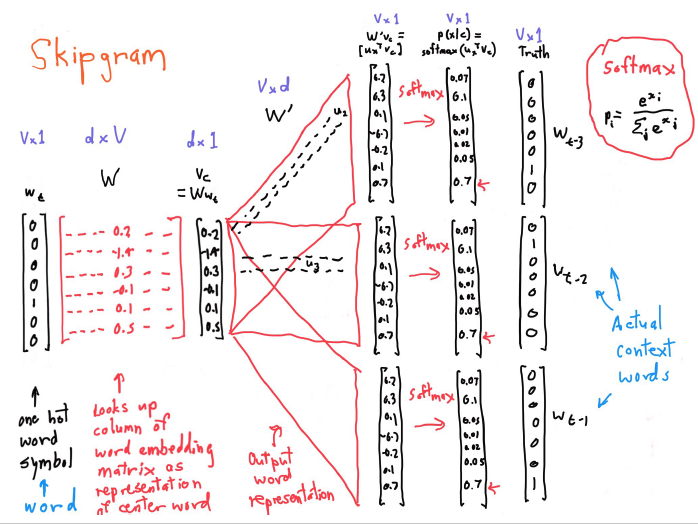
为了训练模型,需要计算所有的 vector gradients,模型参数:
每个单词都有两个 vectors。即作为中心词的 vector,作为 context 的 vector
上式是对center vector 求导,对其他的 output vector 也是一样的
with negative sampling
训练一个二分类的 LR模型,区分
- a true pair:the center word & word in its context window
- a couple of noise pairs: the center word & a random word
softmax归一化因词表大而复杂度高。理论上NCE近似softmax,论文实验也证明只需要采样数k=25,效果等价,速度提升45x。
而负采样又是NCE的特例,当且仅当 k 为词表总数。
实际中负采样数很少,因此近似NCE,又近似softmax,而且负采样公式更简单而被广泛运用。负采样在保证精读的前提下,提升了训练速度,很多大规模分布式模型训练的银弹。
negative sampling 不能得到跟 softmax 一样的效果。negative sampling / NCE / softmax 都可以用来训练词向量,但是只有后两者可以用来训练语言模型(其中 NCE 是 softmax 的渐进近似),negative sampling 不可以。 negative sampling 能训词向量
Continuous bag of words———CBOW
和 skip-gram 是相反的
从context vectors 来预测 center vector
-
count based
- LSA, HAL, COALS, Hellinger-PCA
- Fast training, efficient usage of statistics
- Primarily used to capture word similarity
- Disproportionate importance given to large counts
-
direct prediction
-
NNLM, HLBL, RNN, Skip-gram/CBOW
-
Scales with corpus size, Inefficient usage of statistics
-
Generate improved performance on other tasks
-
Can capture complex patterns beyond word similarity
-