弱监督学习
充分利用人工标注信息、减小标注工作量、将人类经验与学习规则充分结合
这些手动标记的训练集创建起来既昂贵又耗时 ,通常需要花费许多人数月或者数年的成本来进行数据的收集、清理和调试 —— 尤其是在需要领域专业知识的情况下。除此之外,任务经常会在现实世界中发生变化和演变。例如,数据标注指南、标注的粒度或下游的用例都经常会发生变化,需要重新进行标记(例如,不仅要将评论分类为正类或负类,还要引入一个中性类别)。可见,由于数据标注需要付出高昂代价,这种强监督信息是很难获得的。因此,研究者们面对急需解决的数据标注问题,整合了现有的主动学习、半监督学习等研究成果,提出了「弱监督学习」概念,旨在研究通过较弱的监督信号来构建预测模型。1
弱监督学习理论
不完全监督——incomplete supervision
不完全监督,指的是训练数据只有部分是带有标签的,同时大量数据是没有被标注过的。这是最常见的由于标注成本过高而导致无法获得完全的强监督信号的情况。
在训练数据为 D = {(x_1, y_1), …, (x_l, y_l), x_{l+1}, …, x_m},其中 l 个数据有标签、u=m-l 个数据无标签的情况下,训练得到 f:x —> y
在诸多针对不完全监督环境开发的机器学习范式中,主动学习、半监督学习、迁移学习是三种最流行的学习范式。
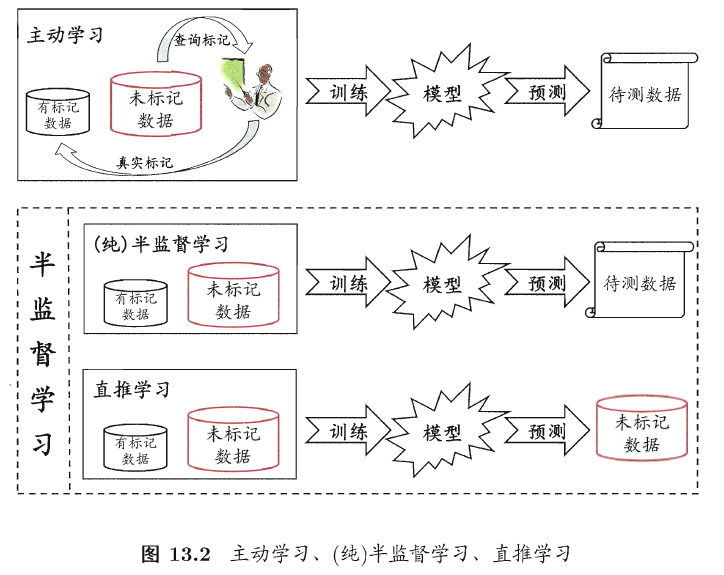
主动学习——active learning
它假设未标注数据的真值标签可以向人类专家查询,让专家为估计模型最有价值的数据点打上标签。在我们只考虑用查询次数衡量标出成本的情况下,主动学习的目标是在提高查询效率,在查询次数尽可能小的情况下,使得训练出的模型性能最好。因此,主动学习需要选择出最有价值的未标注数据来查询人类专家。
而在衡量查询样本的价值时,有两个被最广泛使用的标准:信息量和代表性。
- 信息量: 衡量的是一个未标注数据能够在多大程度上降低统计模型的不确定性
- 代表性: 衡量一个样本在多大程度上能代表模型的输入分布。
这两种方法都有其明显的缺点。
- 基于信息量的衡量方法包括不确定性抽样和投票查询,其主要的缺点是在建立选择查询样本所需的初始模型时,严重依赖于对数据的标注,而当表述样本量较小时,学习性能通常不稳定。
- 基于代表性的衡量方法,主要缺点在于其性能严重依赖于未标注数据控制的聚类结果。
目前,研究者尝试将这两种方法结合起来,互为补充。
半监督学习——semi-supervised learning(SSL)
与主动学习不同,半监督学习是一种在没有人类专家参与的情况下对未标注数据加以分析、利用的学习范式。通常,尽管未标注的样本没有明确的标签信息,但是其数据的分布特征与已标注样本的分布往往是相关的,这样的统计特性对于预测模型是十分有用的。
半监督学习可进一步划分为纯(pure)半监督学习和直推学习(transductive learning)
-
纯半监督学习:假定训练数据中的未标记样本并非待测的数据,
-
直推学习:假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。
实际上,半监督学习对于数据的分布有两种假设:聚类cluster假设和流形manifold假设。
- 聚类假设:假设数据具有内在的聚类结构,因此,落入同一个聚类的样本类别相同。
- 流形假设:假设数据分布在一个流形上,在流形上相近的样本具有相似的预测结果。
可见,两个假设的本质都是相似的数据输入应该有相似的输出。因此,如何更好地衡量样本点之间的相似性,如何利用这种相似性帮助模型进行预测,是半监督学习的关键。
半监督学习的方法主要包括:
生成式方法: 认为有标签数据和无标签数据,都来源于同一个分布
基于图的方法:将所有的数据构造成一张图,图的节点,表示样本,图的边表示样本之间的关系,利用标签传播的技术,将无标签数据打上标签
低密度分割法:就是希望分类面不要穿过密度高的区域
基于分歧的方法:就是构造不同的分类器,从不同的视角去分析数据
本文在这里对这些具体的方法不多赘述,详情请参阅周志华老师的综述文章「A brief introduction to weakly supervised learning」。
伪标签(Pseudo-Labelling)学习
伪标签学习/简单自训练(simple self-training):用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器。
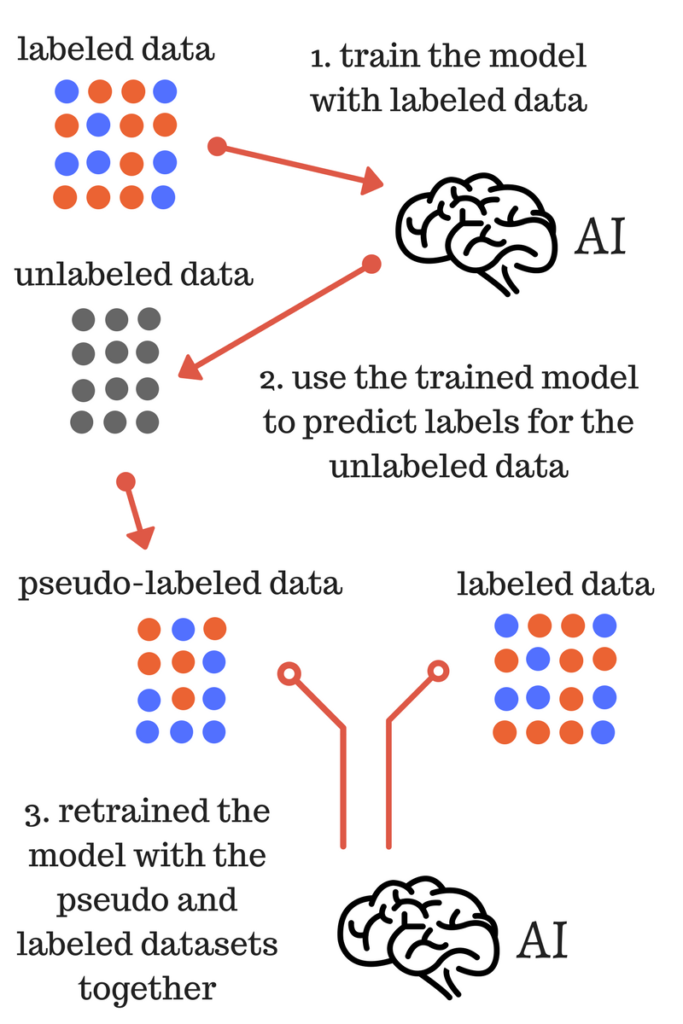
上图反映的便是简单的伪标签学习的过程,具体描述如下:
-
使用有标签数据训练模型;
-
使用训练的模型为无标签的数据预测标签,即获得无标签数据的伪标签;
-
使用2.获得的伪标签和标签数据集重新训练模型;
最终的模型是3.训练得到,用于对测试数据的最终预测。
伪标签方法在实际的使用过程中,会在3.步中增加一个参数:采样比例(sample_rate),表示无标签数据中本用作伪标签样本的比率。
伪标签方法的更加详细介绍以及Python实现可以最后的参考文献。
迁移学习——transfer learning
迁移学习是近年来被广泛研究,风头正劲的学习范式,其内在思想是借鉴人类「举一反三」的能力,提高对数据的利用率。
具体而言,迁移学习的定义为:
- 有源域 Ds 和任务 Ts;
- 目标域 Dt 和任务 Tt,
- 迁移学习的目标是利用源域中的知识解决目标域中的预测函数 f
- 条件是源域和目标域不相同或者源域中的任务和目标域中的任务不相同
在迁移学习研究的早期,迁移学习被分类为「直推式迁移学习」、「归纳迁移学习」和「无监督迁移学习」。
在当下的深度学习社区中,一种常见的迁移学习方法是在一个大数据集上对模型进行「预训练」,然后在感兴趣的任务上对其进行 「调优」。
不确切监督——inexact supervision
即训练样本只有粗粒度的标签。例如,针对一幅图片,只拥有对整张图片的类别标注,而对于图片中的各个实体(instance)则没有标注的监督信息。例如:当我们对一张肺部 X 光图片进行分类时,我们只知道某张图片是肺炎患者的肺部图片,但是并不知道具体图片中哪个部位的响应说明了该图片的主人患有肺炎。该问题可以被形式化表示为:
学习任务为 f: X -> Y,
其训练集为 D = {(X_1, y_1), …, (X_m, y_m)},其中 X_i = {x_{I, 1}, …, x_{I, m_i}}, X_i 属于X,X_i 称为一个包,样本 x_{i, j}属于X_i(j属于{1, …, m_i})。m_i 是 X_i 中的样本个数,y_i 属于 Y = {Y, N}。当存在 x_{i, p}是正样本时,X_i 就是一个正包,其中 p 是未知的且 p 属于 {1, …, m_i}。
模型的目标就是预测未知包的标签。
不确切监督,基本研究的都是 bag learning 或者 multiple instance learning 这些问题。
关注的是有些情况下,虽然给定了标签,但是标签还不够精细,这就是所谓的多实例学习 multi-instance learning,多个实例,构成一个 bag,这个 bag 有一个标签,但是我们最终是希望知道这个标签,属于这个 bag 中的哪个实例,以我们常见的弱监督检测来说,可以把一张图像,看成有多个 local patch 组成的,每个 local path 其实就是一个 instance,而这张图像就是一个 bag,有的时候,我们只会告诉你这张图像,或者这个 bag 属于哪个类,但是对于检测来说,我们还需要进一步确定,这个标签到底属于哪个 local patch,也就是我们所说的实例,所以弱监督检测,其实就是一个多实例学习的问题。
不准确监督——inaccuracy supervision
即给定的标签并不总是真值。出现这种情况的原因有很多,例如:标注人员自身水平有限、标注过程粗心、标注难度较大。
在标签有噪声的条件下进行学习就是一个典型的不准确学习的情况。而最近非常流行的利用众包模式收集训练数据的方式也成为了不准确监督学习范式的一个重要的应用场所。