Relation Extraction
原文链接:https://blog.csdn.net/Kaiyuan_sjtu/article/details/89961674
信息抽取(Information Extraction)是指从非结构化的自然语言文本中抽取出实体、属性、关系等三元组信息,是构建知识图谱的基础技术之一。IE的子任务大概有以下几种:
- 实体识别与抽取
- 实体消歧
- 关系抽取
- 事件抽取
关系抽取的目的是从文本中抽取两个或多个实体之间的语义关系
关系抽取的解决方案主要有以下几类:
-
基于模板的方法(rule-based)
-
监督学习
-
- ML
- DL
-
半监督/无监督学习
-
- Bootstrapping
- Distant supervision
- Unsupervised learning from the web
Relation Classification via Convolutional Deep Neural Network(Zeng/Coling2014)
挺久远的一篇文章,可以算是 CNN 用于文本处理比较早的一批了。在这之前,大多数模型使用的都是 feature-based 或者 kernel-based 方法,不仅处理过程复杂而且算法最终的效果很大程度上依赖于特征设计的有效性。基于此,作者提出了一种基于CNN的深度学习框架,可以自动提取输入中多层次的特征(词层面和句子层面)如下所示:
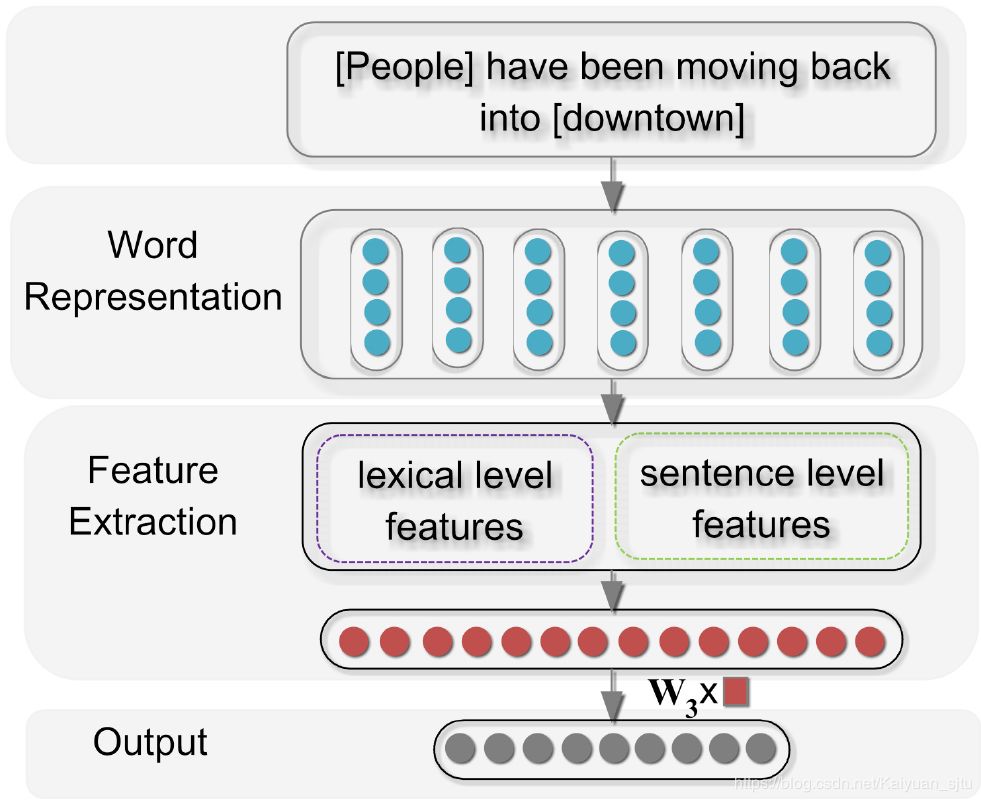
Word Representation Layer
标准操作word embedding,不过用的不是现在主流的 word2vec、glove 等等,而是预训练的来自 Word representations: A simple and general method for semi-supervised learning 的词向量。
Feature Extraction Layer
特征抽取模块设计了两种features:词法特征(Lexical-Feature)和句法特征(sentence-level feature)
Lexical-Feature 词法特征
在确定实体关系任务中,词法特征是非常重要的。传统的词法特征提取主要包括实体本身、名词性实体对以及实体之间的距离等等,这些特征很大程度上依赖于现有的NLP工具,对RE任务最重效果容易引起误差放大。但是在有了 word embedding 之后就可以对词法特征设计更恰当的特征,一共有五部分:
| Features | Remark | |
| ——– | —————————— | |
| L1 | Noun1 | |
| L2 | Noun2 | |
| L3 | Left and right tokens of noun1 | |
| L4 | Left and right tokens of noun2 | |
| L5 | WordNet hypernyms of nouns | |
举个例子,对于句子 S: [People] have been moving back into [downtown]
- L1: People
- L2: downtown
- L3: x_s,have
- L4: into,x_e
- L5: 在wordnet中找到people和downtown的上位词
注意:以上都是word embedding形式
Sentence Level Features
句法特征提取方案如下:
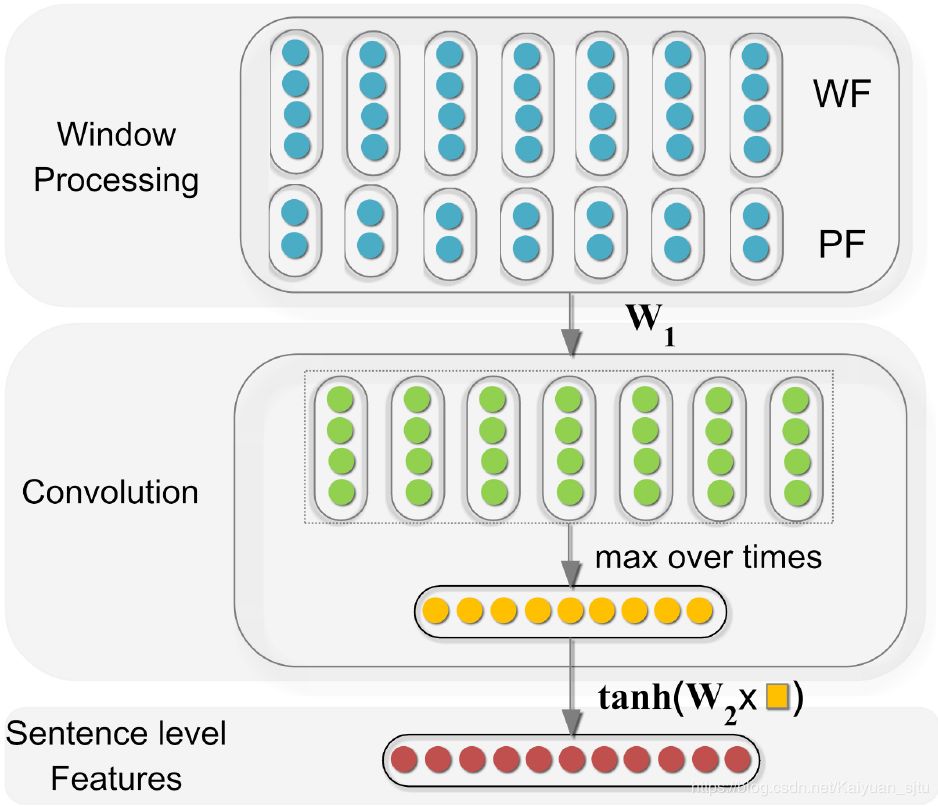
在第一步Window Processing设计了两个特征输入,一个是单词特征(Word Features), 一个是位置特征(Position Features)
- Word Features 就是 word embedding,不过加入了 n-gram 的信息;
- Position Features 就是位置信息,每个context单词与实体对词语之间的相对距离。这样设计的目的是为了突出两个entity的作用
最后对每一个单词将Word Features和Position Features拼接起来,得到features维度为:
得到句子的抽象表达之后,送入卷积层进行特征提取。不过这里的卷积核设计有点奇怪只有一层将Window Processing层的输出进行线性映射:
接着为了每一维度提取最重要的特征,设计了max-pooling层:
最后通过非线性激活层得到句子特征表示:
Output Layer
output层的输入是将上一层词法和句法层面提取出来的特征进行拼接,并送入softmax层进行关系的多分类。
损失函数为交叉熵损失,优化方式为SGD。
总结
以上就是基于CNN进行关系抽取的整体思路。总结一下:
- 整个模型需要学习的参数:
- word embedding(X)
- position embedding (P)
- 卷积核权重矩阵(W_1)
- sentence-level 最后的全连接层参数矩阵 (W_2)
- 用于softmax的全连接层参数矩阵(W_3)
- 引入位置信息,CNN 相对 RNN 较弱的是对长距离位置的建模,这里加上PE后可以很有效缓解这个问题,之后的很多研究(CNN,attention等)都有PE的身影;
- 卷积层那块感觉有点单一,因为只有一个线性的映射特征提取不够充分
- 虽然整个框架在现在来看是非常简单的设计,但是经典呀
Relation Extraction: Perspective from Convolutional Neural Networks(Nguyen/ACL2015)
15年的文章,在之前Zeng的模型基础上加入了多尺寸卷积核,并且更”偷懒地”丢弃了人工的词法特征,完全依靠 word embedding 和 CNN 来做特征。完整的框架和文本分类领域非常经典的Text-CNN很像
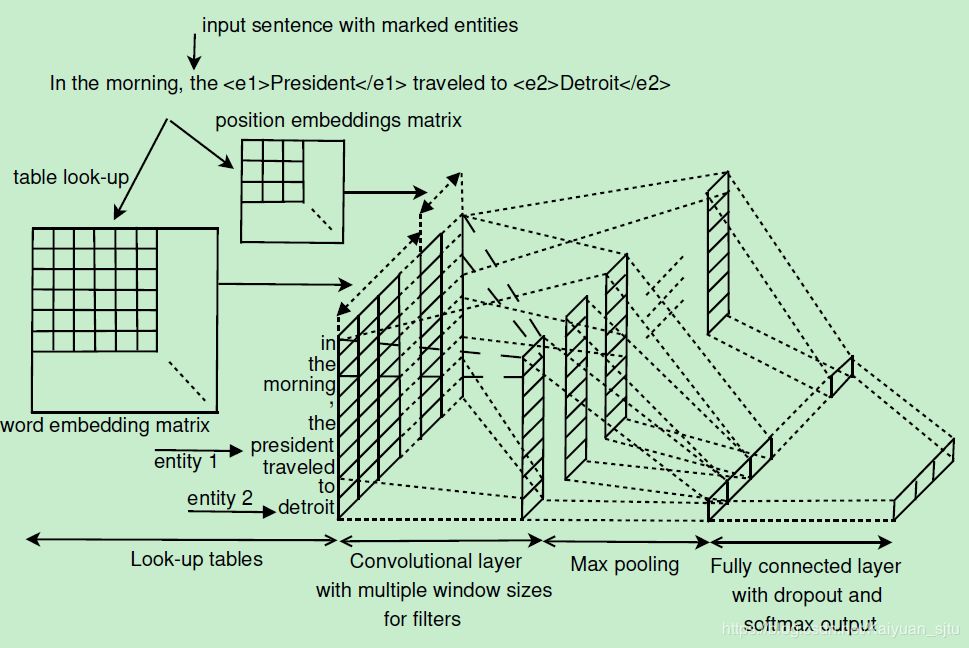
- 在Zeng的基础上使用了多尺寸卷积核,更全面提取特征
- 丢弃人工词法特征,端到端训练更方面
- 进一步研究关系抽取问题,考虑了该问题中数据集分布不平衡
- CNN框架比较简单,因此效果提升不是很明显
Classifying Relations by Ranking with Convolutional Neural Networks(Santos/ACL2015)
直接看模型,也是非常传统的文本CNN框架,但是作为顶会文章肯定是有一些亮点的。5
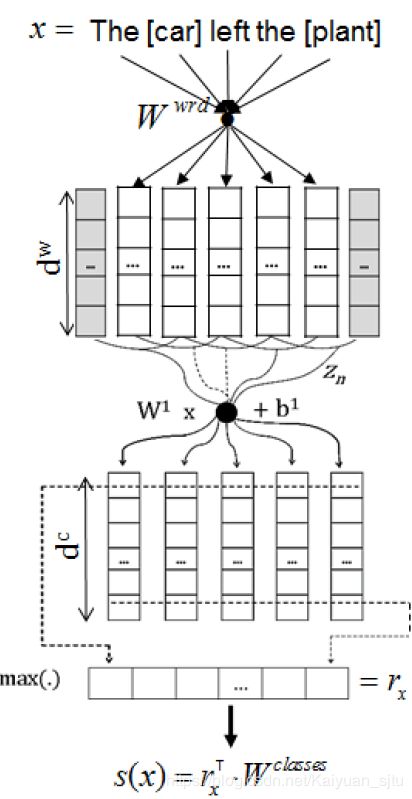
创新点
1. 损失函数
不同于一般多分类使用的 softmax+cross-entropy 损失函数,这里独特地设计了一种margin-based ranking loss:
: 输入句子sent
: sent对应的正确标签
: sent对应的错误标签
:正标签对应的大于0的margin
:错误标签对应的大于0的margin
: 正样本对应的得分
: 负样本对应的得分
: 缩放系数
右边第一项计算的是正样本的得分只有大于 margin 的时候才不会有损失,否则就需要计算损失,即得分越高越好;
右边第二项计算的是负样本的得分只有小于 margin 才不计算损失,即负样本得分越小越好;
是不是跟SVR的感觉有点像?这样整体的损失函数的目的就是更加清晰地区分正负样本。
2. 对Other类别的处理
Other类别表示两个标定的entity没有任何关系或者是属于不存在与给定关系集合中的关系,对于模型来说都是噪音数据。
经过之前是实践(参考github),发现确实模型在对Other类型的处理部分并不是很理想,拉低了最终的得分。
因此作者提出在训练阶段,直接不考虑Other这一类别,即对于Other的训练数据,令上一节中损失函数第一项为0。
那么在预测阶段,如果其他类别的score都为负数,那么就分类为Other。从实验结果看,这个点的提高有2%左右。
Relation Classification via Multi-Level Attention CNNs(Wang/ACL2016)
使用 CNN + Attention 来实现关系分类,设计了较为复杂的两层 attention 操作
- 第一层是输入attetion,关注实体与句子中单词之间的联系;
- 第二层是卷积之后的attention pooling,关注的是标签与句子之间的关联。
另外在模型的损失函数部分,作者也单独自定义了一个loss,改进了之前提及的margin-based ranking loss。模型整体框架如下所示,下面我们将其分解来仔细看一下是怎么运行的。
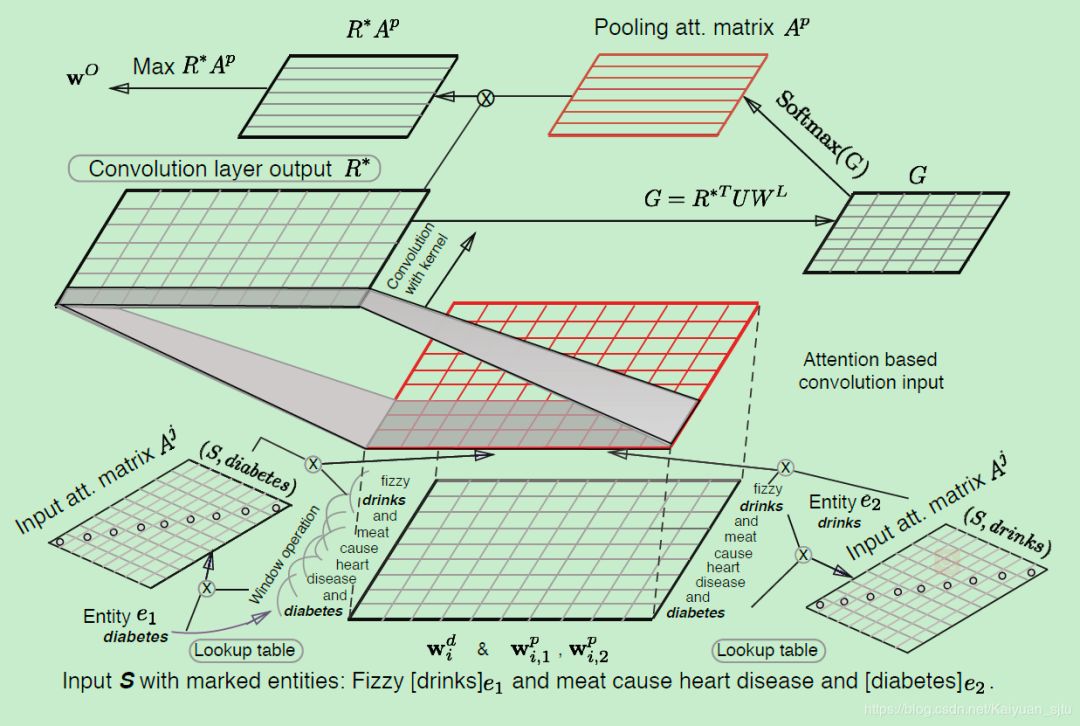
Input Representation
模型输入是一个句子 以及两个标注好的实体。常规操作,先利用预训练的word2vec映射成词向量矩阵,同时加入了位置向量,目前为止得到的输入形式为: 之后为了更好地融入句子的上下文信息,选取了大小为k的窗口滑过句子(为了中心词左右单词个数相同,最好选取k为计数),得到最终输入表示为: 其中
Input Attention Mechanism
经过预处理后得到我们的输入表示应该就像上图中的最下层的矩阵的形式了,然后对其进行第一层attention操作提取实体与单词的关联信息。
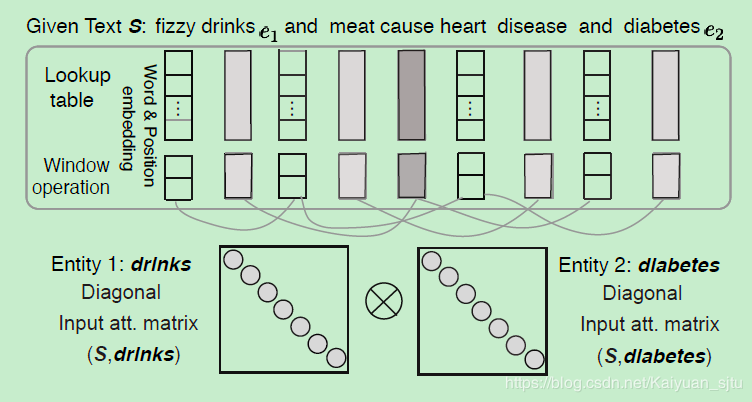
-
首先定义两个对角矩阵和,对应两个实体。其中矩阵中对角线元素表示为句子中单词 同该实体之间的关联性,具体是通过单词 和实体 word embedding的內积计算而来
-
网络训练的目标之一就是这两个对角矩阵
-
通过softmax归一化计算句子中每个单词相对不同实体的权重
-
这样每个词都存在两个权重系数,分别对应两个实体。用这两个权重去和输入矩阵 Z 进行交互,文中给出了三种交互形式:
- average:
- concat:
- quadratic difference:
-
经过第一层attention后句子表示为
小结
- 考虑到 CNN 提取信息能力有限,设计了两层Attention来补充,与文本分类的《Hierarchical Attention Networks for Document Classification》有些像;
- 针对该任务自定义了损失函数,效果比使用传统softmax+cross entropy有所提升;
- 在设计Input attention过程,两个矩阵A1和A2完全可以使用一维的向量,不懂为什么要设计成对角矩阵;
- SemEval-2010 Task 8 上的 F1 值达到了 88
Relation Classification via Recurrent Neural Network(Zhang 2015)
考虑到CNN对于文本序列的长距离建模不够理想,作者提出使用RNN来进行关系分类的建模。
整体框架如下:包括了word embedding layer—> Bi-RNN layer—> Max Pooling layer。
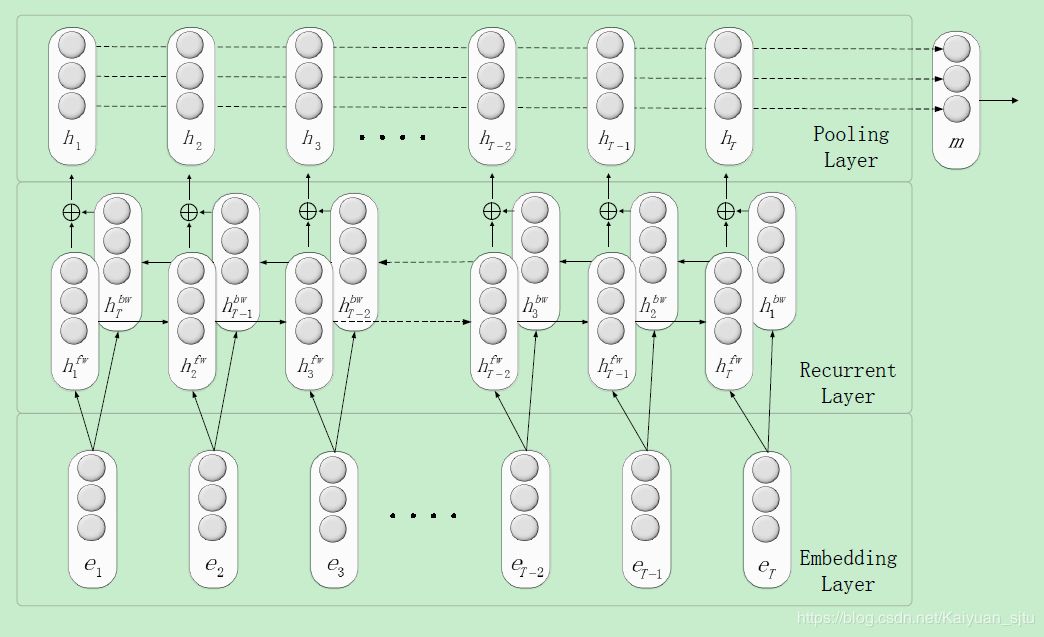
整体属于比较简单易懂的RNN传统框架,并没有加什么其他trick。
相较于之前的Position Embedding,这里使用了Position indicators来替换,这是因为在RNN中,单词之间的位置信息已经会被自动地建模进去。
PI就是使用四个标签来标记两个实体对象,比如对于句子:people have been moving back into downtown在加入PI之后变成了<e1> people </e1> have been moving back into <e2> downtown </e2> ,其中<e1>, </e1>, <e2>, </e2>就是标签,在训练的时候直接将这四个标签当成普通的单词即可。
Bidirectional Recurrent Convolutional Neural Network for Relation Classification(Cai/ACL2016)
提出了一种基于最短依赖路径(shortest dependency path, SDP)的深度学习关系分类模型,文中称为双向循环卷积网络(bidirectional recurrent convolutional neural networks,BRCNN)。
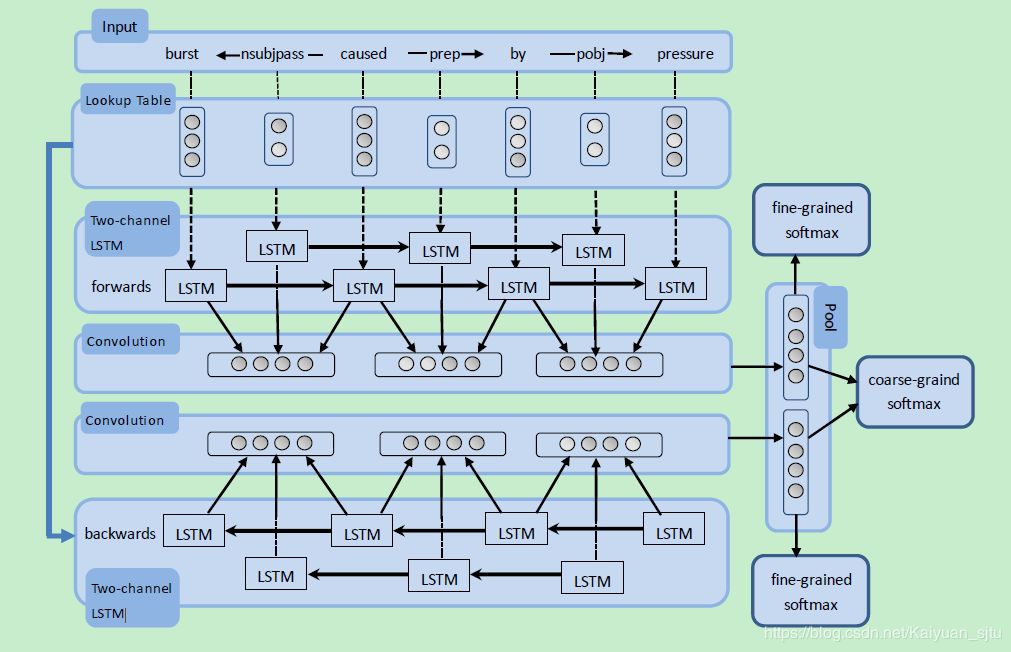
在每个RCNN中,将SDP中的 words 和 words 之间的 dependency relation 分别用 embeddings 表示,并且将SDP中的words之间的dependency relation 和 words 分开到两个独立 channel 的 LSTM,使它们在递归传播的时候不互相干扰。
在convolution层把相邻词对应的LSTM输出和它们的 dependency relation 的 LSTM 输出连结起来作为 convolution 层的输入,在 convolution 层后接max pooling。
在pooling层后接softmax分类,共有三个softmax分类器,两个RCNN的 pooling 分别接一个 softmax 做考虑方向的(2K + 1)个关系分类,两个RCNN的pooling连到一个softmax做不考虑方向的(K + 1)个关系分类。
Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification(Zhou/ACL2016)
这篇文章使用的是LSTM,避免了RNN在处理长文本时存在的梯度消失问题。另外加入了attention layer可以更有效地关注实体对之间的关系。整体框架如下图
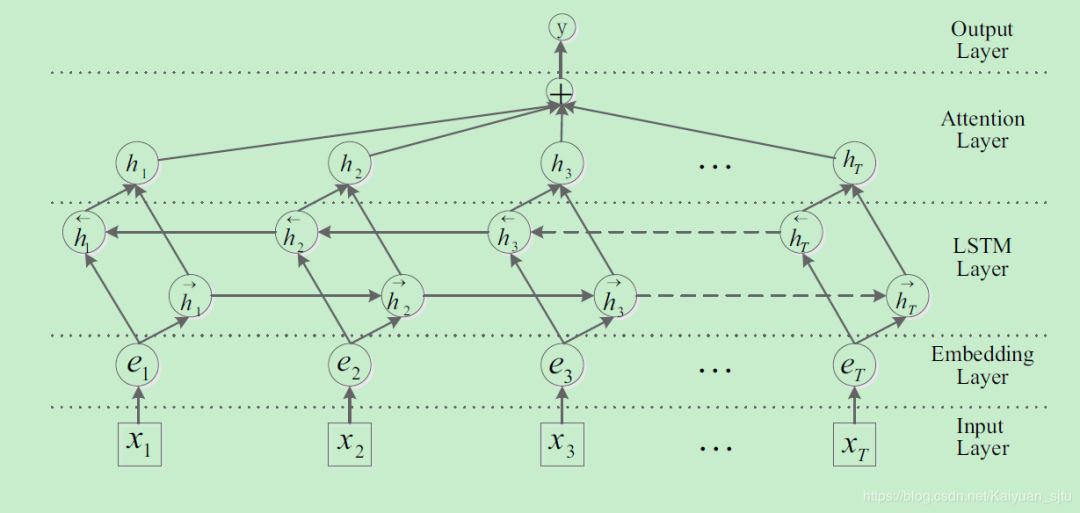
整个模型可以分为以下几层:
- Embedding层:为了与之前的模型作比较,本文选取的词向量为senna-50和glove-100
- Bi-LSTM层:输入为embedding层的句子向量表示,输出为每个时间步前向后向网络hidden state的逐元素相加;
- Attention层:vanilla attention,其中key和value为BiLSTM层的输出向量,query为自定义的可训练的向量
- Output层:使用softmax和交叉熵损失
文章中提出的BiLSTM + Attention可以做为很多NLP 任务的baseline,效果强大。
关系分类总结
- 输入层标配:word embedding + position embedding
- 特征提取层可以选取: CNN/RNN/LSTM/Attention等,效果最好的是加上attention层的模型叠加
-
损失函数:实验证明针对该任务 margin-based ranking loss 比传统多分类 softmax + cross entropy 表现要好
- 可以改进的方向:单纯从神经网络的结构出发,改进的余地很小了,因为这个数据集很封闭, 可以利用的信息仅仅是这些sentence 以及 标注的word entity。 在上述的基础上可能可以考虑的方向,从两个target word与relation的关系上加约束。
Distant Supervision(DS)
远程监督提出来的初衷是为了解决标注数据量太小的问题, 第一个将远程监督运用到关系抽取任务中的是Distant supervision for relation extraction without labeled data
If two entities have a relationship in a known knowledge base, then all sentences that mention these two entities will express that relationship in some way.
基本假设: 如果两个实体在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。
具体步骤:
(1)从知识库中抽取存在关系的实体对;
(2)从非结构化文本中抽取含有实体对的句子作为训练样例,然后提取特征训练分类器。
存在问题:假设太强会引入噪音数据,包含两个实体的句子不一定和数据库中的关系一致。
改进方法: 提出多示例学习(Multi Instance Learning)的方法
多示例学习可以被描述为:
假设训练数据集中的每个数据是一个包(Bag),每个包都是一个示例(instance)的集合,每个包都有一个训练标记,而包中的示例是没有标记的;
如果包中至少存在一个正标记的示例,则包被赋予正标记;而对于一个有负标记的包,其中所有的示例均为负标记。
(这里说包中的示例没有标记,而后面又说包中至少存在一个正标记的示例时包为正标记包,是相对训练而言的,也就是说训练的时候是没有给示例标记的,只是给了包的标记,但是示例的标记是确实存在的,存在正负示例来判断正负类别)。
通过定义可以看出:
与监督学习相比,多示例学习数据集中的样本示例的标记是未知的,而监督学习的训练样本集中,每个示例都有一个一已知的标记;
- 与非监督学习相比,多示例学习仅仅只有包的标记是已知的,而非监督学习样本所有示例均没有标记。
- 但是多示例学习有个特点就是它广泛存在真实的世界中,潜在的应用前景非常大。
from http://blog.csdn.net/tkingreturn/article/details/39959931
Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks(Zeng/ EMNLP2015)
可以说是作者自己之前的那篇文章的改进版,提出了两点现存的缺陷以及相对应的改进方式:
-
远程监督标注数据的噪音很大,使用多示例学习的方式;
-
原始方法大都是基于词法、句法特征来处理, 无法自动提取特征。而且句法树等特征在句子长度边长的话,正确率很显著下降。提出改进的Piecewise Convolutional Neural Networks (PCNNs)
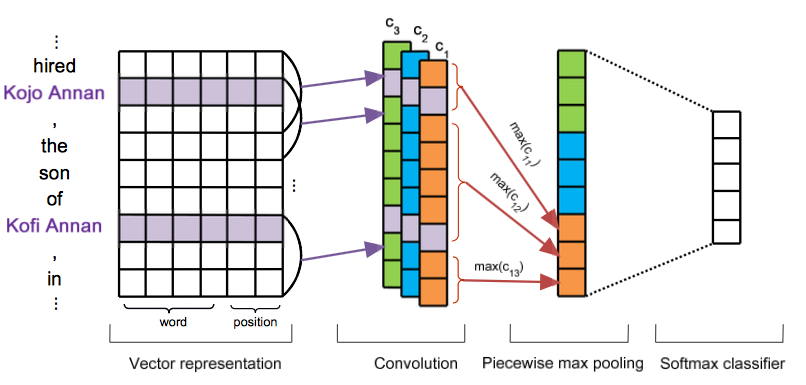
网络的设计就是很简单的 embedding + cnn + pooling。需要提一下的是这里对 pooling 层进行了改进,不再使用整个channel的唯一max,而是对卷积后得到的输出划分成三块,分别是两个实体部分和一个不包含实体的部分,这样对这三块做 piecewise max pooling,得到三个向量。最终将三个卷积核的输出做一样的操作拼接起来后做softmax分类,最终得到输出向量o。
Multi-instance Learning
首先给出几个定义:
- bag:数据中包含两个entity的所有句子称为一个bag
- : 表示训练数据中的T个bags,每个bag都有一个relation标签
- : 表示第i个bag中有 个instance,也就是句子,假设每个instance是独立的
- 便是给定 的网络模型的输出(未经过 softmax),其中表示第 r 个 relation 的 score
这样,经过 softmax 就可以计算每一个类别的概率:
模型的目的是得到每个bag的标签,所以损失函数是基于bag定义的,这里采用了“at-least-once assumption”,即假设每个bag内都肯至少有一个标注正确的句子,那么就找出bag中得分最高的句子来求损失函数:
其中

Neural Relation Extraction with Selective Attention over Instances(Lin/ACL2016)
在上一节的CNN基础上引入句子级别的Attention机制。也是针对远程监督过程会引入错误标签的问题,指出在Zeng 2015年的CNN模型中只考虑了每一个bag中置信度最高的instance,这样做会忽略bag中的其他句子丢失很多的信息。因此提出对一个bag中的所有句子经过CNN处理后再进行Attention操作分配权重,可以充分利用样本信息。模型整体框架如下:
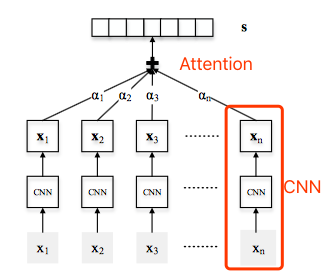
其中最底层的输入xi是某一个bag中的句子,接着对每一个句子都做同样的CNN操作(这一部分与前一节PCNN相同),最终得到每个句子的表示ri 。然后为了更好地利用bag内的句子信息,对所有的instance衡量对该bag对应的标签的权重: 其中alpha为权重系数,文中给出两种计算方式:
Average: 直接做平均,错误样本的噪声很大;
Selective Attention: 就是一般的 key-query-value 的 attention 计算。 其中ei表示attention score,用于计算某个句子与该bag对应的relation之间的匹配程度。
在经过attention就得到了每个bag中所有句子的表示。最后输出首先将这个向量与relation matrix做一个相似度计算后送入softmax归一化成概率: 【注意】 在模型的test阶段,由于bag并没有给出的标签,因此在attention计算过程与train阶段不一样。处理方式为:对每一个relation,都做一遍上述的Selective Attention操作得到每个relation的得分,最后预测的结果就是取max就好啦。但是这样做会导致inference阶段会比较慢。
Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks(Jiang/Coling 2016)
这篇文章主要是先分析了PCNN模型的缺陷,然后提出了几点改进方案:
-
at-least-once assumption假设太强,仅仅选取每个bag中的一个句子会丢失很多信息;解决方案是对bag内所有的sentence之间做max-pooling操作,可以提取出instance之间的隐藏关联;
-
single-label learning problem:在数据集中有大约18.3%的样本包含多种relation信息,设计了一种多标签损失函数,即使用sigmoid计算每一个类别的概率,然后判断该bag是否可能包含该类别。
基于以上两点提出了multi-instance multi-label convolutional neural network (MIMLCNN), 模型整体框架如下
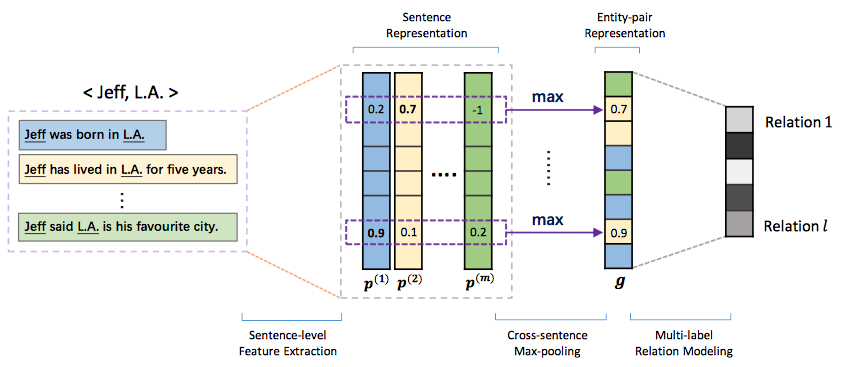
Sentence-level Feature Extraction
目的就是将bag中的所有instance表示成向量形式,这里采取的就是PCNN模型,一模一样。
Cross-sentence Max-pooling
这一部分的设计就是为了解决“at-least-one assumption”,文中提出另一种假设:
A relation holding between two entities can be either expressed explicitly or inferred implicitly from all sentences that mention these two entities.
做法也很直观,直接对所有instance的向量每一个维度取最大值: 文中还提出可以使用average-pooling的方式,但是相比max-pooling,ave-pooling会增大错误标签的噪音,效果不如max-pooling。
Multi-label Relation Modeling
上述过程得到的向量g经过一个全连接层计算每一个relation的score: 由于是多个标签预测,这里不再采用softmax,而是对于每一个relation做sigmoid,如果结果超过某个阈值(这里是0.5),则认为该instance包含该种relation: 接着设计了两种不同的损失函数作了对比:
Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions(Ji/AAAI2017)
论文的主打的主要有两点:
- 第一点依然是针对Zeng的文章中提出的“at-least-one assumption”提出改进方案,采取的措施是对句子级别进行attention操作;
- 第二点是认为在知识库中对实体的描述也能反映很多的信息,建议将Entity Descriptions加入到模型中
模型的整体框架如下:
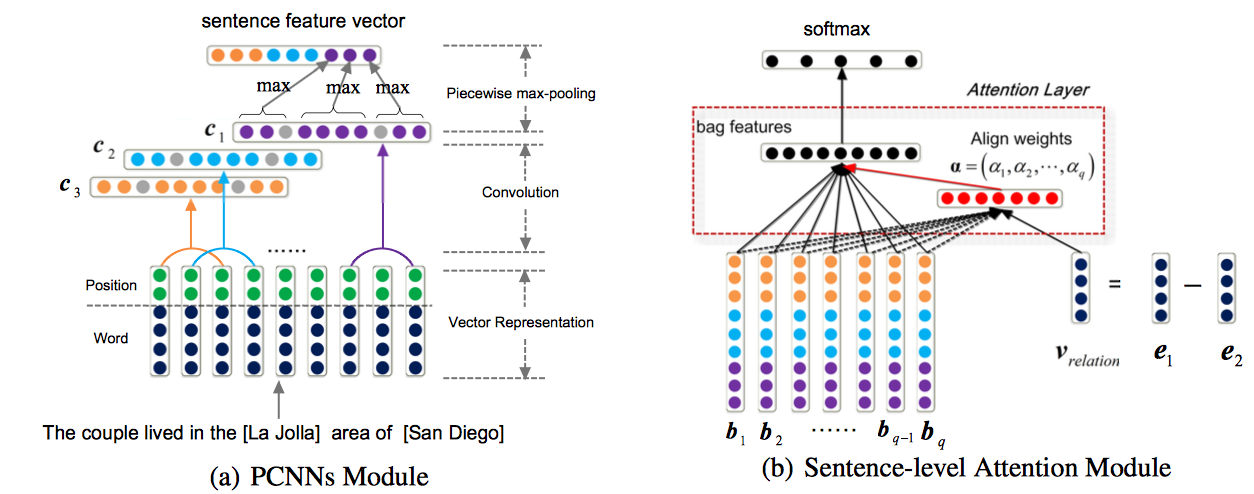
APCNN Module
这一部分跟 Neural Relation Extraction with Selective Attention over Instances的工作非常像,唯一不同的地方在做attention时对query的选择不同。
【Selective Attention】选择的是bag的真实标签,这样在训练时是没有问题的,不过在inference阶段由于样本bag没有标签,所以需要计算所有relation的得分选取最高的那一类,这样的话再test过程的计算量会很大。
本文【Sentence-level Attention】采用的则是受word embedding特性的启发,认为relation的表示可以通过两个实体之间的运算得到: 计算 sentence-level attention:
过 softmax:
Entity Descriptions
到目前为止可以说没什么创新点,在这部分作者提出了将Entity Descriptions的信息融入模型,可以更好的帮助最后的relation判断。其实现也很简单:
-
输入为 entity 的 word embedding,通过一层简单的 CNN + max-pooling 得到 description 的向量表示
-
文中提出的一个约束是:尽可能使得前面得到的 entity 的 word embedding 与 这里得到的 entity 的 description embedding 接近,这样的动机很简单,就是将 entity 的描述信息融入到模型中,这部分的LOSS直接使用二范距离
Loss Function
APCNN阶段的损失函数为:
Entity Dscriptions阶段的损失函数为:
所以最终整体的损失函数为:
小结
- 在attention过程对relation embedding的处理采用了TransE的思路,可以说非常具有说服力
- 另外加入的实体描述建模也可以更有效地为模型融入更多信息,同时还会加强entity向量表示的准确性。
Neural Relation Extraction with Multi-lingual Attention(Lin/ ACL2017)
这篇文章是在Lin 2016年 Selective Attention的基础上进行改进,将以前仅仅研究单一语言扩展到多语言信息抽取。
多数已有的研究都致力于单语言数据,而忽略了多语言文本中丰富的信息。
多语言数据对信息抽取任务有以下两个优势:
- 一致性: 一个关系事实在多种语言中都有一定的模式,而这些模式的关系在不同语言中大致上一致。
- 互补性: 不同语言的文本可以相互借鉴,另外数据多的语言能够帮助数据少的语言提升总体性能
基于以上两点,文章提出了Multi-lingual Attention-based Neural Relation Extraction(MNRE),对于给定的两个实体,他们在不同语言中的句子集合, 其中 表示j种语言的集合中有nj个句子。模型最终的为每种关系打分f(T,r)选取得分最高的relation。
模型整体框架如下:
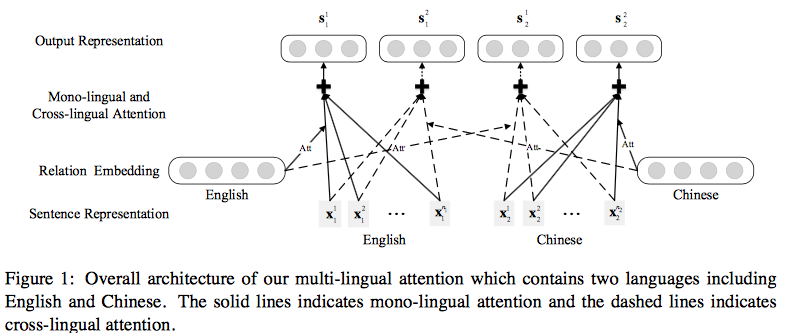
Sentence Encoder
句子特征抽取这一部分跟Lin 2016年 Selective Attention的工作几乎一样,之前已经有详细介绍,这里就不再啰嗦啦
Multi-lingual Attention
为了获取多语数据中的信息,设计了两种attention操作:单语言之间attention和多语言之间attention。
其中Mono-lingual Attention为上图中实线部分,其实现与Lin 2016年 Selective Attention相同。
下面主要介绍 Cross-lingual Attention,表现为上图中虚线部分。 假设 j 和 k 分别代表了不同的两种语言,
-
首先计算语言 j 的句子集合与语言 k 的标签之间的一致性程度,得到attention score ei:
-
接着用 softmax 归一化 attention score 得到 attention distribution:
-
最后用 attention distribution 去判定语言 j 中句子的重要性程度
这样如果有m种语言,那么最终结果就会得到m∗m种对于实体对的表示: 然后把这些向量经过全连接层+softmax后得到每个relation的概率。为了更好地考虑不同语言的特点,可以在全连接层在共享权值的基础上加上每种语言特有的权值矩阵,如对应第 k 中语言由 组成:
试验分析及总结
- 作者在文章后半部分做了很多对比试验,非常有说服力地验证论文的价值
-
文章一大创新点就是利用多语言数据之间的一致性与互补性运用到数据抽取任务,其中多语分析也被用于其他NLP任务,比如情感分析,信息抽取等;
- 虽然说更多的数据代表更多的信息,但是原始多语言数据的获取确是一大难点
Deep Residual Learning for Weakly-Supervised Relation Extraction (Huang /EMNLP 2017)
本文从之前研究的一层CNN扩展到了更深的CNN网络(9层),使用的是在图像领域非常有效的ResNet。residual learning将低层和高层表示直接连接,还能解决deep networks的梯度消失问题。本文使用shortcut connection。每个block都是一个两层convolution layer+ReLU。整体模型如下所示:
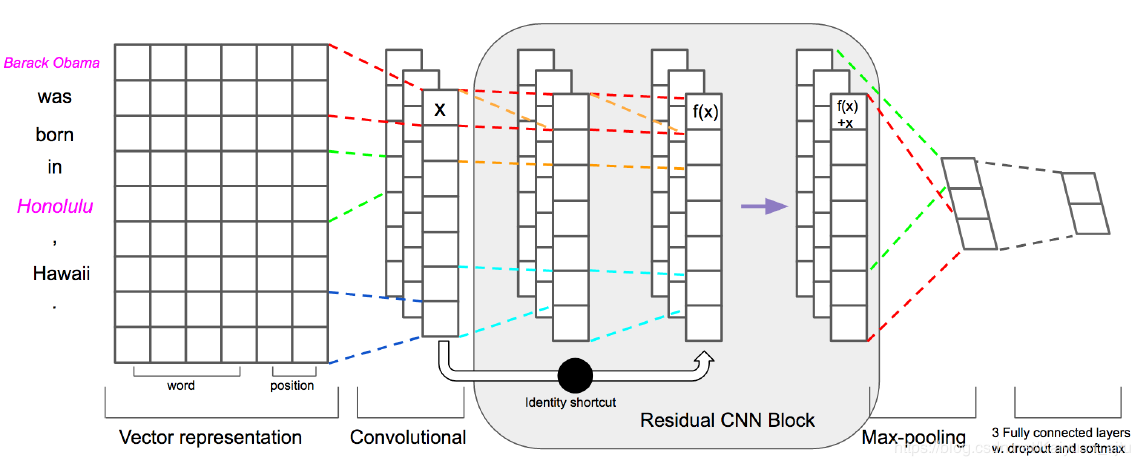
至于为啥ResNet对于信息抽取任务会有效,文中给出了两点原因:
- 第一点是,假如浅层、中层和高层分别抽取到词法、句法和语义的信息的话,那么有时候忽略中间的句法信息,直接将语法和语义信息结合也可以work;
- 第二点是,ResNet可以有效缓解深度网络中的梯度消失问题,而这个操作可以有效减轻远程监督数据中的噪音(???不懂)
Learning with Noise: Enhance Distantly Supervised Relation Extraction with Dynamic Transition Matrix(Luo/ACL 2017)
本文的重点也是在于如何解决远程监督数据的噪音问题。前人的工作,主要是降噪,即从噪音数据中提取出正确标记的样本。
作者在这篇论文中提出既然数据中的噪音是无法避免地存在的,为何不在模型中学习噪音的分布,即给噪音数据建模,从而达到拟合真实分布的目的。
于是在训练过程对每一个instance引入了对应的transition matrix,目的是:
- 对标签出错的概率进行描述
- 刻画噪音模式
由于对噪音建模没有直接的监督,提出使用一种课程学习(curriculum learning) 的训练方式,并配合使用矩阵的迹正则化(trace regularization) 来控制transition matrix在训练中的行为。整体的模型框架如下图所示
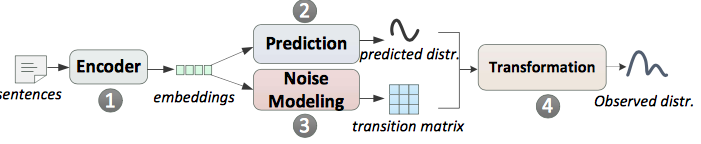
Sentence-level Modeling
句子级别的建模,主要考虑输入是一个句子。分为三部分:
(1)上图中的①+②过程就是之前介绍的PCNN_+ FC + SOFTMAX输出对应relation概率的模型。 (2)Noise Modeling: 对于一个句子,通过 PCNN + FC 得到 后使用 softmax 计算 transition matrix: : 给定正确标签 i,预测结果为类别 j 的条件概率
: 表示类别 i 和类别 j 混淆可能性的权重向量
: 类别总数
: 偏置项
注意:在训练时会对每个 instance 都建立 transition matrix,但是其中的权重向量 是全局共享的。
(3) Observed Distribution:通过transition matrix与预测向量 p 相乘,可以得到最终的分布o: 在模型训练阶段,使用观测分布o;
但是在inference阶段,直接使用 prediction distribution ,因为模型已经学习到的噪音分布模式可以防止prediction受其影响
Bag Level Modeling
bag级别的建模,输入是一个bag里的多个句子。和上面 sentence level 唯一不同的就是如何表示出bag的向量。这里可以使用句子级别的attention操作,在之前都有过介绍,就不在细述。
Curriculum Learning based Training
在训练过程中,参考大家普遍的做法是,对于模型输出 o, 直接计算 o 和 label 的 loss, 也就是 CrossEntrophy (CE) + l2 正则作为损失函数。
这样做不能保证 p 能表示真实分布。原因在于在训练的初始阶段,我们对于噪音模式没有先验知识,这样 T 和 p 都不太可靠,这样会使得训练陷入局部最优。因此我们需要一种技术来保证我们的模型能够逐步适应训练噪音数据,于是引入了课程学习。
课程学习的思想:starting with the easiest aspect of a task, and leveling up the difficulty gradually
课程学习的训练方法可以引入先验知识以提高transition matrix的有效性,例如,我们认为地将训练数据分为两部分,一部分相对可靠,一部分相对不可靠
Trace Regularization
迹正则是用来衡量噪音强度的。当噪音很小时,transition matrix会是比较接近单位矩阵(因为ij之间混淆性很小,同类之间的转移概率很大,接近1,这样转移矩阵就会接近单位矩阵) trace(T)越大,表明T和单位矩阵越接近,也就是噪音越少。对于可靠的数据trace(T)比较大,不可靠的数据trace(T)比较小。
迹正则的另一个好处的降低模型的复杂度,减小过拟合。
训练
直接看最终的损失函数,由三部分组成:
第一部分是观测分布的损失
第二部分是预测分布的损失
第三部分是迹正则
alpha,beta分别表示训练过程中红每个损失的重要程度。 训练过程:
一开始,让alpha=1。随着训练的进行,sentence encoder 分支有了基本的预测能力。并逐渐减小beta, alpha。逐渐减小对于trace的限制,允许更小的trace来学到更多噪音。随着训练的进行,越来越关注于学习噪音模式。
另一方面,如果我们有数据质量的先验知识,就可以利用这些先验来进行课程学习。具体来说就是将数据集分成相对可靠和相对不可靠两部分,先用可靠的数据集训练几个epoch, 再加入不可靠的数据集继续训练。同时利用迹正则,对于可靠数据集,trace(T)可以适当地大一些,对于不可靠的数据集,则要让trace(T)小一些。
小结
- 文章的出发点非常好,既然噪音是在数据中无法避免的,那我们训练阶段就去学习这种噪音分布特征,然后在测试阶段就可以有效避免;
- 提出了global transition matrix,用于得到从真实预测分布到实际观测到的包含噪音分布的映射关系;之后有进一步优化到了Dynamic transition matrix,依输入句子的不同而改变,粒度更细,效果更好;
- 提出了curriculum learning的训练模式,课程学习属于一种从易至难的任务学习,比随机顺序学习更好,避免学习出无意义的局部最优;
Effectively Combining Recurrent and Convolutional Neural Networks for Relation Classification and Extraction(SemEval 2018)
本文的模型也非常易懂,ensemble了前面例举过的CNN和LSTM,如下图所示
- 模型的输入是word embedding + POS + relative position embedding
- 对于CNN部分:一层多个卷积核convolutional layer + ReLU + max-pooling layer + fully-connected layer with dropout + softmax
- 对于RNN部分:双向LSTM(使用 dynamic,不用 padding)+ fully-connected layer with dropout + softmax
- 将以上的 ensemble 网络训练20次,将得到的概率值平均后作为最终每个分类的得分
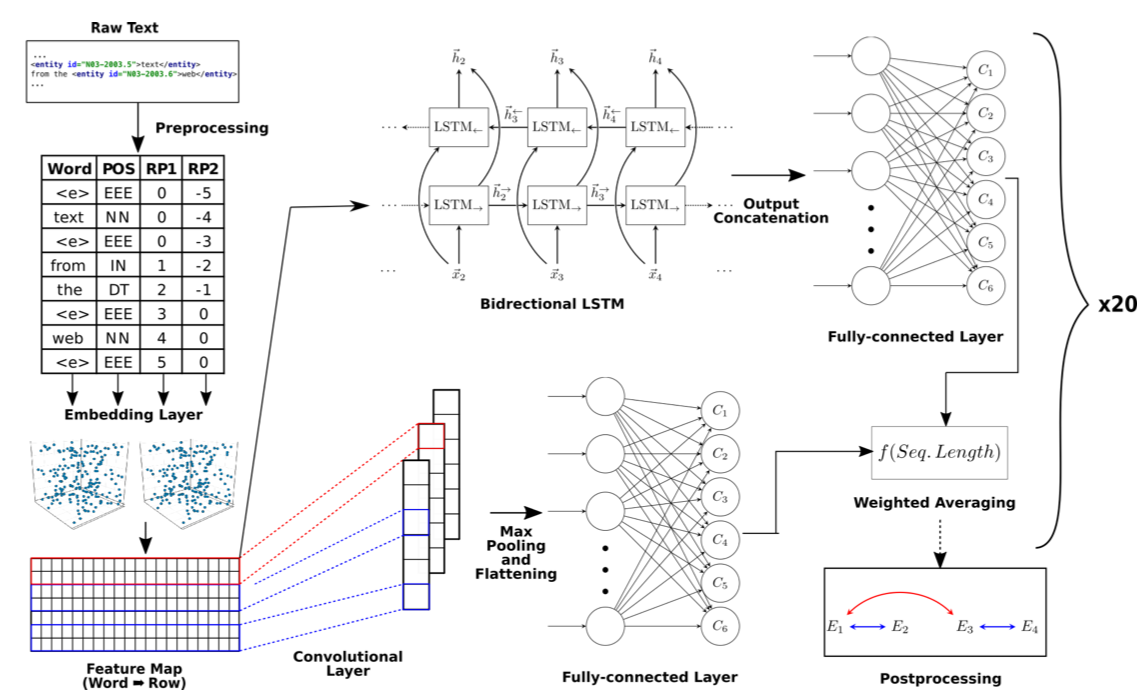
Domain-specific word embeddings
使用 gensim 为该任务训练了特定领域的词向量,尝试了100,200,300维的词向量,最终200维表现最好。
Cropping sentences
考虑到最终决定relation类别的是句子两个实体之间的部分,于是将所有句子两个实体之间的部分切分出来当成训练样本。此外通过对数据分析发现当句子长度大于一定阈值时,类别的概率会大大降低,通过实验得出阈值设定为19的时候效果最佳
Cleaning sentences
原始数据集中有些自动标注的样本包含了噪音实体,例如
Using entity tags
其实就是之前介绍过的 Position Indicator,用于告诉模型实体在句子中的位置。
Relative order strategy & number of classes
一种数据增广方式:句子反转。将非对称的关系句子按字反转之后,实体对的前后关系发生反转,他们之前的关系也就发生了反转,于是使用一种替换的方式直接将实体中间的字换成表达相反关系的token。 例如图中表达的是“由…组成的关系”, 前者“corpus”由后者“text”组成。将句子反转之后,他们之间的位置反转,中间的token “ from a “ 表示”由…组成的关系“相反的关系。这样新生成的句子虽然是语法上不通,但是可以提升Performace。
Upsampling
对于subtask2,数据集出现样本极度不平衡现象,类别为None的样本占了大多数。于是对所有数据上采样,也就是网络输入每次保证正负样本的比例是固定的(1:1)
Combining predictions
作者做实验的时候发现,单独使用RNN或者CNN, 效果都差不多,但是两种模型ensemble的时候效果会有提升。更进一步的结果是,作者发现RNN模型对长一些的句子比CNN效果好。于是本文使用如下公式对RNN的prob加权。 其中是对一个句子的长度拉伸表示(区间为[-0.5, 0.5]),句子越长,权重越高
Post-processing
六类关系中有五种是非对称的,一种是对称的。由于进行了句子反转,所以翻转后的句子结果不可能为对称关系,需要将这种情况下的预测改变为得分第二高的类别。
还有一种情况是,subtask2中,每个实体只能属于一个关系,如果出现一个实体同时出现在两个关系中,需要选择更短的或者频率更高的或者随机输出。
之前介绍的关系抽取系列文章主要是属于pipeline形式的,即第一步用实体识别将关系对抽取出来,第二步才是对关系对的分类,这样的做法会导致误差的传递。另外有一种解决方案是端到端的joint model,即上面的两步同时完成,这一思路在直觉上会更优。
End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures(Miwa/ACL2016)
作者指出目前关系抽取的做法都是两个子任务(实体抽取及实体关系抽取)组成的pipeline形式,在最终效果上仍有欠缺。
于是论文提出了一种端到端的神经网络模型,包括一个双向序列结构LSTM-RNN用于实体抽取,一个依存树形LSTM-RNN用于关系抽取,两个LSTM-RNN模型参数共享,整体框架如下所示,主要分为三个layer。
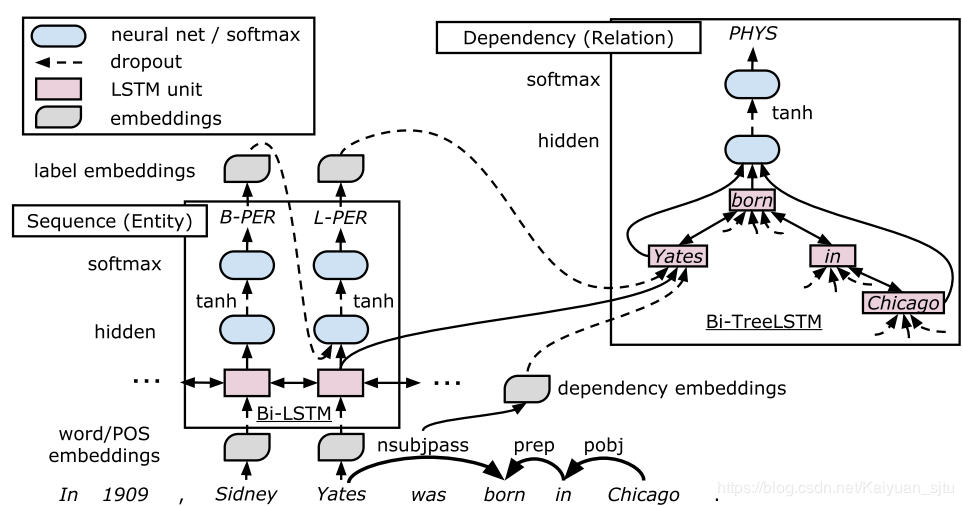
Embedding layer
不同于常规的只采用词向量 ,这里还包括了词性向量 , 依存句法标签和实体标签。
Sequence layer
拆开来看其实这就是一个命名实体识别任务(NER描述可参考【论文笔记】IDCNN & Lattice LSTM for NER),用的是双向LSTM,标签记号为BILOU(Begin, Inside, Last, Outside, Unit)。解码decoding阶段采用从左至右贪婪搜索的方式。
Dependency layer
使用 tree-structured BiLSTM-RNNs( top-down 和 bottom-up ) 来对实体之间的关系建模。输入是 Sequence layer的输出 , dependency type embedding 以及 label embedding , 输出是 dependency relation 。
第一项是 bottom-up LSTM-RNN 的 top LSTM unit,代表实体对的最低公共父节点(the lowest common ancestor of the target word pair p);第二、三项分别是两个实体对应的 top-down LSTM-RNN 的 hidden state。 关系分类主要还是利用了依存树中两个实体之间的最短路径(shortest path)。主要过程是找到 sequence layer 识别出的所有实体(认为在Sequency layer阶段预测出的带有L或U标签的为候选实体对),对每个实体的最后一个单词进行排列组合,再经过 dependency layer 得到每个组合的,然后同样用两层 NN + softmax 对该组合进行分类,输出这对实体的关系类别。
Training Tricks
- scheduled sampling: 来自论文Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks,大致思路是以一定概率用golden label来代替decode阶段的predicted label,减轻误差传递的可能性。
- entity pretraining: 来自论文Curriculum learning of multiple tasks,课程学习的思想。做法是先用训练数据预训练实体抽取模型,第二部再是训练整个模型。
Joint Entity and Relation Extraction Based on A Hybrid Neural Network(Zhou/2017)
本文提出一种 joint learning 的关系抽取框架,用一个混合神经网络来识别实体,抽取关系,不需要额外的手工特征;
另外一个创新是考虑到了entity tag之间的距离。整体框架如下图,包括了三个网络,都没有什么特别的trick,比较容易看懂。
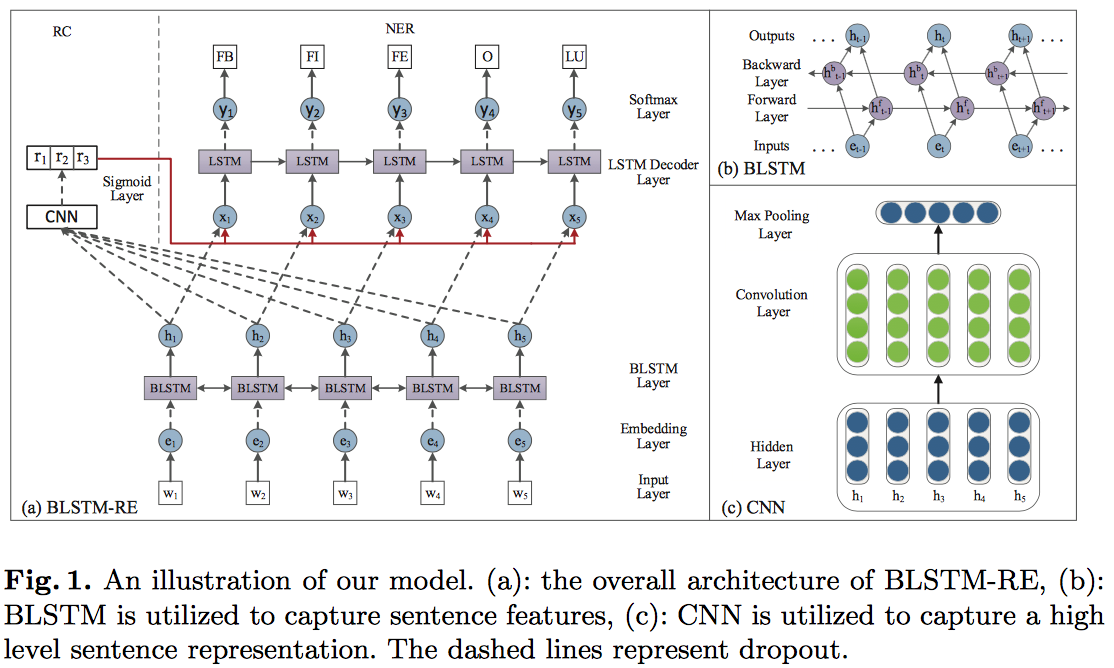
具体的,对于输入句子通过共用的 word embedding 层,然后接双向的 LSTM 层来对输入进行编码。然后分别使用一个 LSTM 来进行命名实体识别(NER)和一个 CNN 来进行关系分类(RC)。
相比现在主流的 NER 模型 BiLSTM-CRF 模型,这里将前一个预测标签进行了 embedding 再传入到当前解码中来代替 CRF 层解决 NER 中的标签依赖问题。
在进行关系分类的时候,需要先根据 NER 预测的结果对实体进行配对,然后将实体之间的文本使用一个 CNN 进行关系分类。所以该模型主要是通过底层的模型参数共享,在训练时两个任务都会通过后向传播算法来更新共享参数来实现两个子任务之间的依赖。
Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme(Zheng/ACL2017)
本文提出了一种新型的序列标注方案,将联合抽取问题转换为序列标注问题。
The Tagging Scheme

标注方案如上,每一个词都有一个标签:
- O:others,和该任务无关的词标签
- 非O(三部分组成):
- 实体位置 信息:BIES(Begin, Inside, End,Single)
- 关系类别 信息:relation type,来自预定义的关系集合
- 关系角色 信息: 1 or 2,代表在一个三元组中的第一个实体还是第二个实体
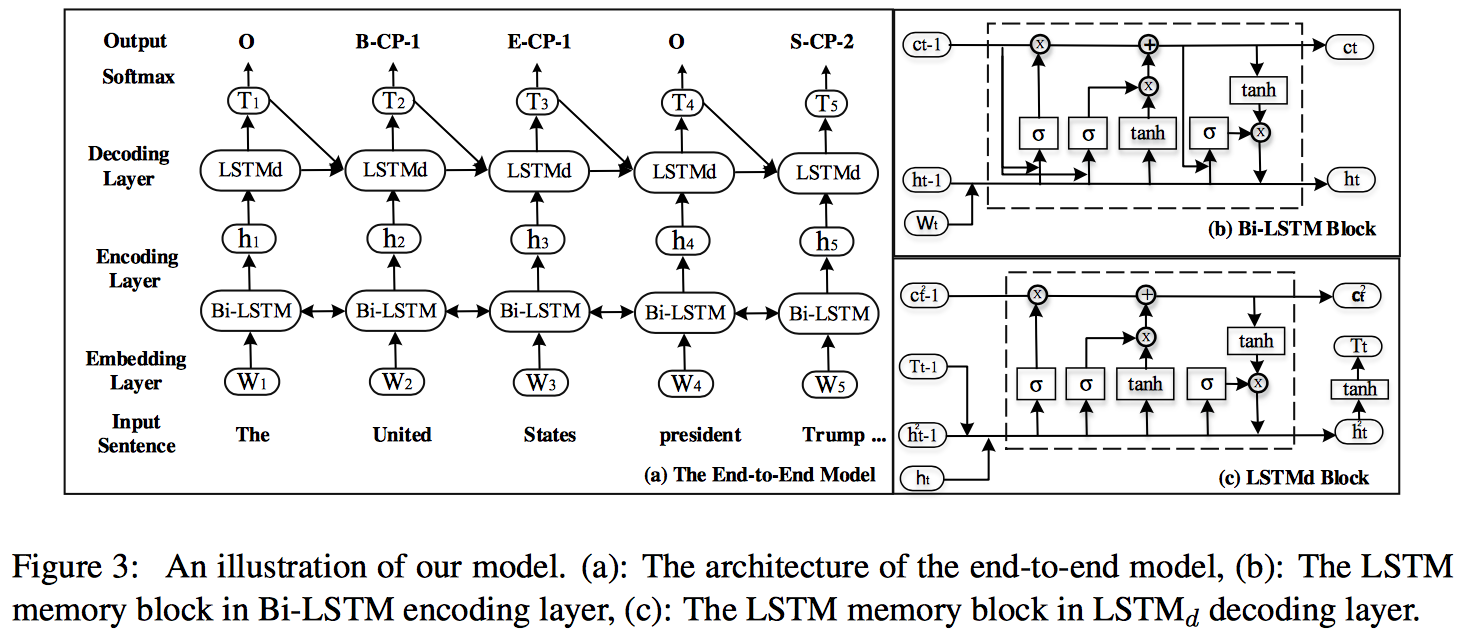
端到端的模型如上,主要包括两个部分:Bi-LSTM的encoder和LSTM的decoder。
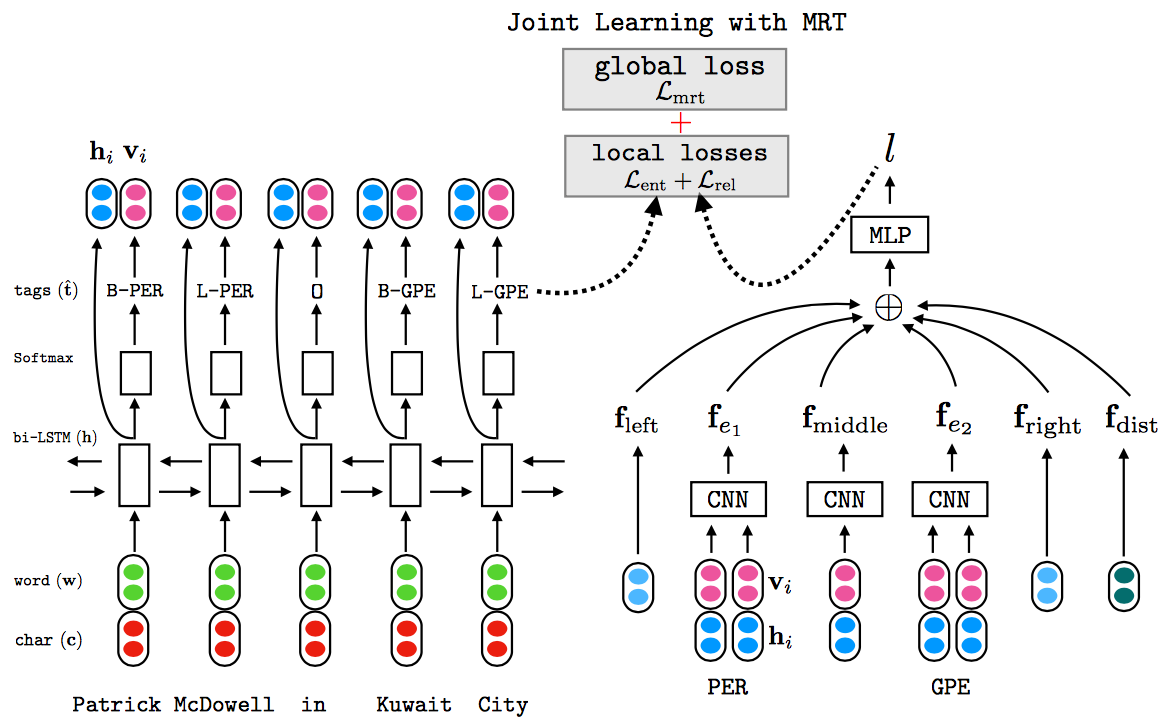
Extracting Entities and Relations with Joint Minimum Risk Training(Sun/NAACL2018)
将最小风险训练方法(minimum risk training,MRT)引入联合关系抽取任务,提供了一种轻量的方式来加强实体抽取和关系抽取两个子模块的关联。MRT方法的优势在于优化句子级别的损失而不是词语级别,这样可以使得模型学习到更多global information。与Miwa的联合模型类似,将实体抽取任务看做是序列标注问题,将关系抽取任务看做是多分类问题,之后将这两个子任务进行联合误差训练。模型如下