ROC 曲线
ROC——receiver operating characterisitc, 接受者操作特征
-
X 轴:False Positive Rate(FPR),,1-Specificity,分类器预测的正类中实际负例(FP)占所有负例(FP+TN)的比例。FPR越大,预测正类中实际负类越多
-
Y 轴:True Positive Rate(TPR),,Sensitivity,分类器预测的正类中实际正例(TP)占所有正例(TP+FN)的比例。TPR越大,预测正类中实际正类越多。其实就是 Recall
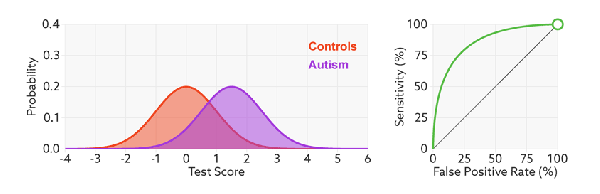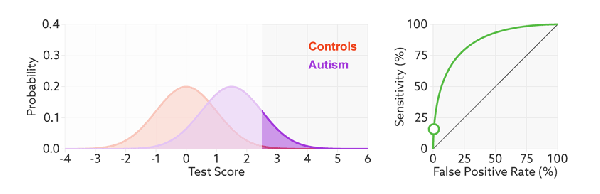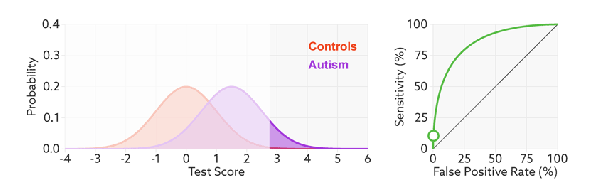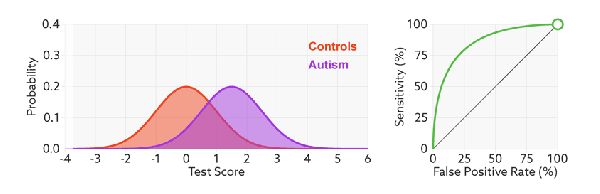
- 理想目标:TPR=1,FPR=0,即图中(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好,Sensitivity、Specificity越大效果越好。TPR越大越好,FPR越小越好,但这两个指标通常是矛盾的。为了增大TPR,可以预测更多的样本为正例,与此同时也增加了更多负例被误判为正例的情况。
- 曲线分析:ROC曲线距离左上角越近,证明分类器效果越好。如果一条算法1的ROC曲线完全包含算法2,则可以断定性能算法1>算法2。这很好理解,此时任做一条 横线(纵线),任意相同TPR(FPR) 时,算法1的FPR更低(TPR更高),故显然更优。很多时候两个分类器的ROC曲线交叉,无法判断哪个分类器性能更好,这时可以计算曲线下的面积AUC,作为性能度量。
- 左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对
- 斜线左上的点(TPR>FPR),说明医生A的判断大体是正确的
- 斜线上的点(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半
- 下半平面的点(TPR<FPR),这个医生说你有病,医生C的话我们要反着听

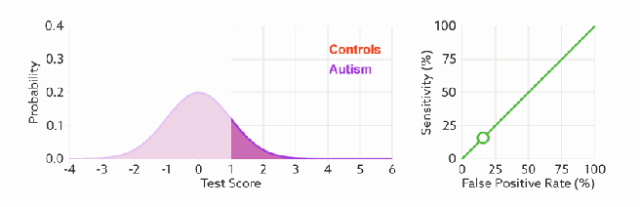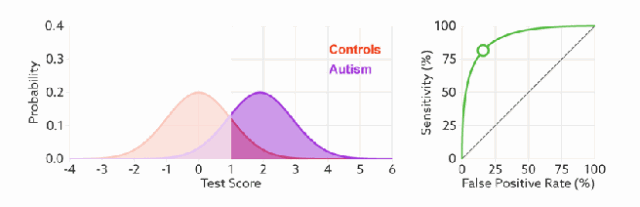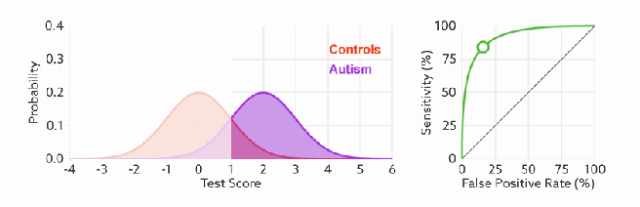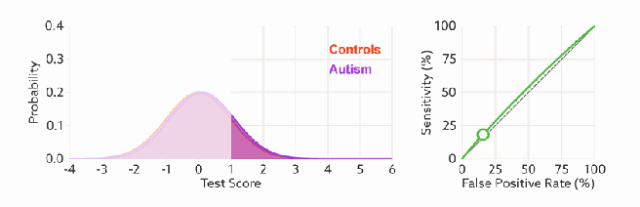
假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
如何判断 ROC 曲线的好坏?
FPR表示模型虚报的响应程度,而TPR表示模型预测响应的覆盖程度。我们所希望的当然是:虚报的越少越好,覆盖的越多越好。所以总结一下就是TPR越高,同时FPR越低(即ROC曲线越陡),那么模型的性能就越好。
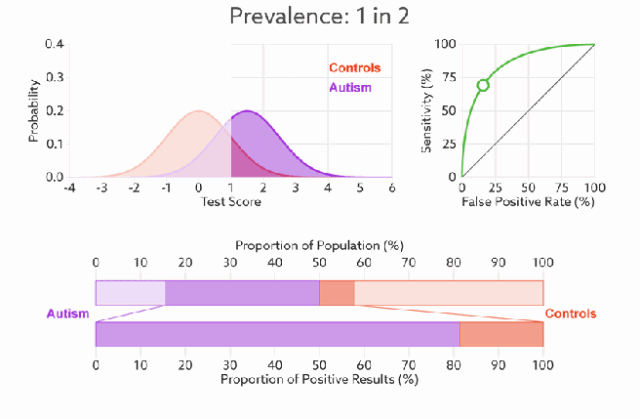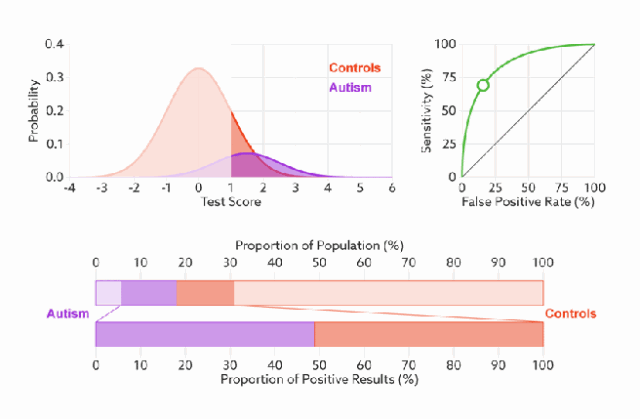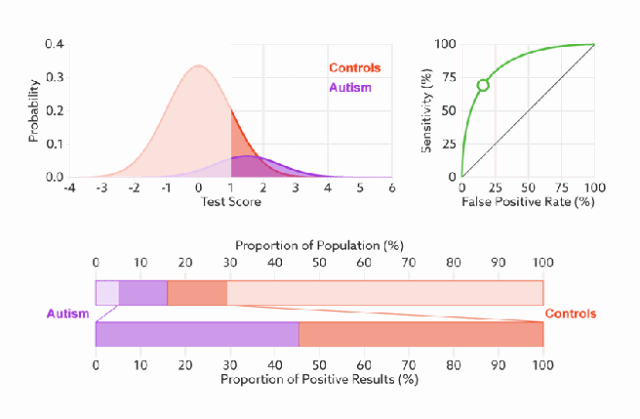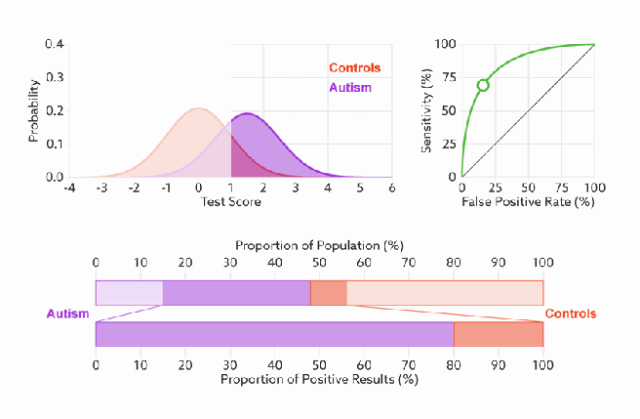
ROC 曲线无视样本不平衡
无论红蓝色样本比例如何改变,ROC曲线都没有影响。
AUC 值
AUC——Area under Curve,ROC 曲线下的面积。AUC 作为数值,可以直观的评价分类器的好坏,值越大越好。
AUC值是一个概率值,随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
- AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- 0.5 - 0.7:效果较低,但用于预测股票已经很不错了
- 0.7 - 0.85:效果一般
- 0.85 - 0.95:效果很好
- 0.95 - 1:效果非常好,但一般不太可能
- AUC = 0.5,跟随机猜测一样,模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
AUC 物理意义:任取一对正负样本,正样本的预测值大于负样本的预测值的概率
计算方法
- 由于我们的测试样本是有限的。我们得到的AUC曲线必然是一个阶梯状的。因此,计算的AUC也就是这些阶梯下面的面积之和。这样,我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。但是,这么 做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此 时,我们就需要计算这个梯形的面积。
- 计算正样本的预测值大于负样本的预测值的概率。在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。这和上面的方法一样,样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。具体来说就是,统计所有的 M × N (M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score 相等的时候,按照0.5 计算。然后除以 M × N。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
- 第三种方法实际上和上述第二种方法是一样的,但是复杂度减小了。它也是首先对 score 从大到小排序,然后令最大 score 对应的 sample 的 rank 为 n,第二大 score 对应 sample 的 rank 为 n - 1,以此类推。然后把所有的正类样本的 rank 相加,再减去 M - 1种两个正样本组合的情况。得到的就是所有的样本中有多少对正类样本的 score 大于负类样本的 score。然后再除以 M × N。即
为何使用 ROC 和 AUC 评价分类器
因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。
在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。
对于正负样本分布大致均匀的问题,ROC曲线作为性能指标更鲁棒。
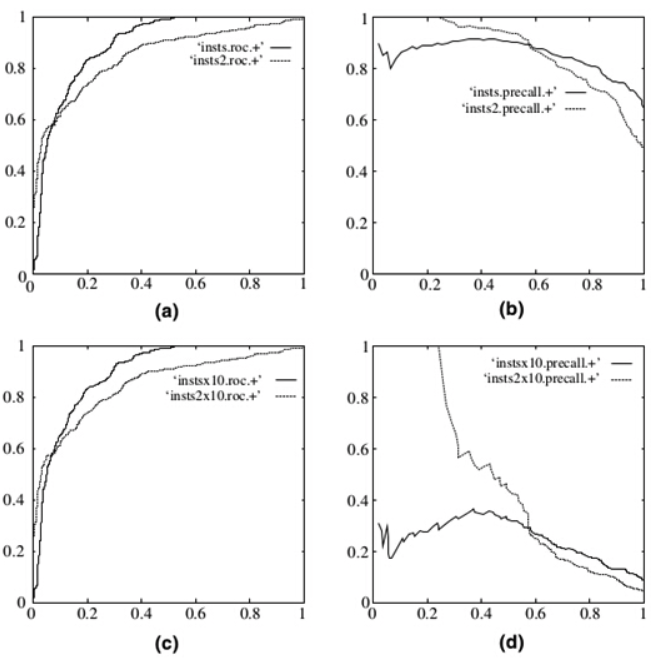
下图是 ROC 曲线和 Presision-Recall 曲线的对比:(a)和(c)为Roc曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
PRC 曲线的优势
在正负样本分布得极不均匀(highly skewed datasets),负例远大于正例时,并且这正是该问题正常的样本分布时,PRC比ROC能更有效地反应分类器的好坏,即PRC曲线在正负样本比例悬殊较大时更能反映分类的真实性能。例如上面的(c)(d)中正负样本比例为1:10,ROC效果依然看似很好,但是PR曲线则表现的比较差。举个例子,
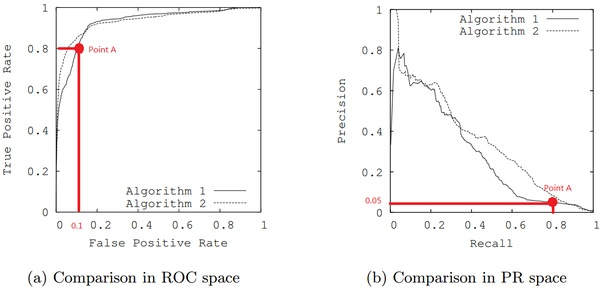
单从图(a)看,这两个分类器都比较完美(非常接近左上角)。而从图(b)可以看出,这两个分类器仍有巨大的提升空间。那么原因是什么呢? 通过看Algorithm1的点 A,可以得出一些结论。首先图(a)和(b中)的点A是相同的点,因为TPR就是Recall,两者是一样的。
假设数据集有100个正样本。可以得到以下结论:
由图(a)点A,可得:TPR=TP/(TP+FN)=TP/所有正样本 =TP/100=0.8,所以TP=80。
由图(b)点A,可得:Precision=TP/(TP+FP)=80/(80+FP)=0.05,所以FP=1520。
再由图(a)点A,可得:FPR=FP/(FP+TN)=FP/所有负样本=1520/所有负样本=0.1,所以负样本数量是15200。
由此,可以得出原数据集中只有100个正样本,却有15200个负样本!这就是极不均匀的数据集。直观地说,在点A处,分类器将1600 (1520+80)个样本预测为positive,而其中实际上只有80个是真正的positive。 我们凭直觉来看,其实这个分类器并不好。但由于真正negative instances的数量远远大约positive,ROC的结果却“看上去很美”,因为这时FPR因为负例基数大的缘故依然很小。所以,在这种情况下,PRC更能体现本质。
Accuracy/Precision/Recall/F1
Accuracy=(TP+TN)/(TP+TN+FP+FN)
Precision=TP/(TP+FP)
Recall=TP/(TP+FN)
F1= , BalancedScore, Precision 和 Recall 的调和平均数