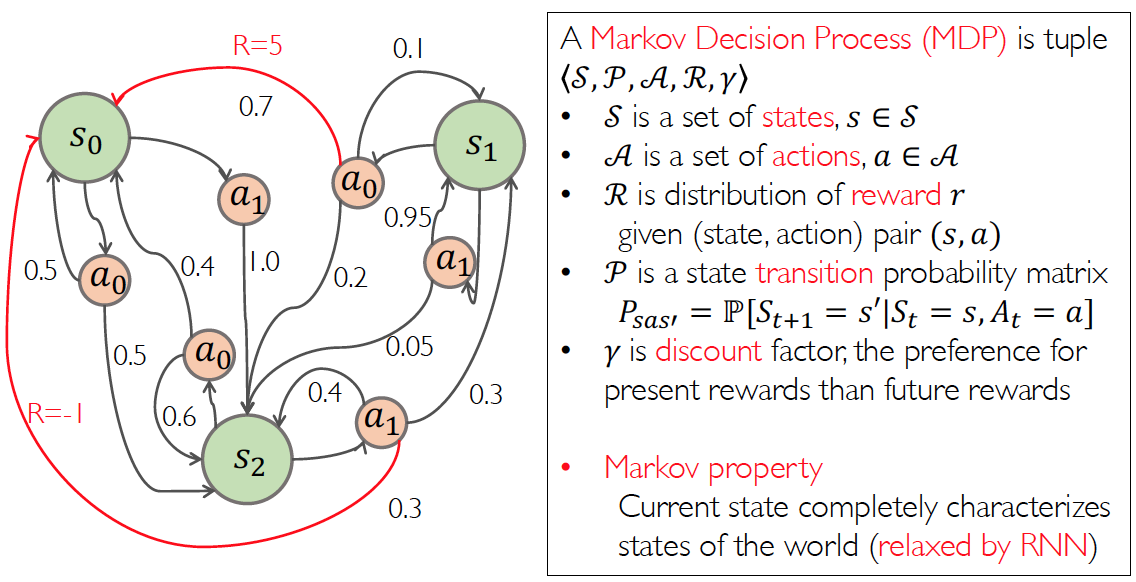
Markov Decision Process(MDP)

Policy
A policy specifies what action to take in each state
- Deterministic policy: (for a state, only one action is taken)
- Stochastic policy: (requires sampling to take action)
Objective: find optimal to maximize the expected sum of rewards with
Value Function
-
(State) Value function is a prediction of the future reward
- How much reward will I get from state s under policy
-
(Action) Q-value function (quality) is a prediction of the future reward
- from state s and action a, under policy
-
Optimal Q-value function is maximum value under optimal policy
Bellman Equation
Q-value function can be decomposed into a Bellman equation
Optimal Q-value function also decomposes into a Bellman equation
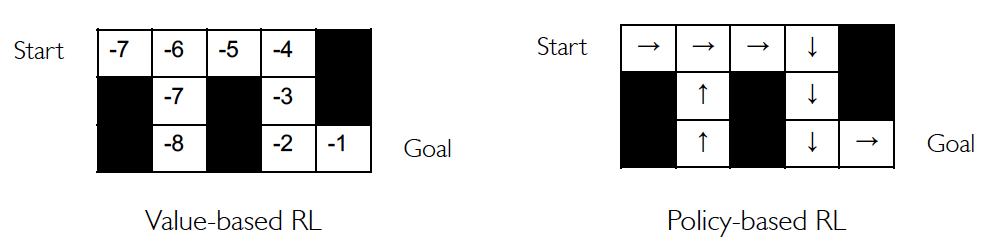
Value-based RL
- Estimate the optimal Q-value function
- This is the maximum value achievable under any policy
Q-Learning(DQN)
Represent the Q-value function by Q-network with weights w
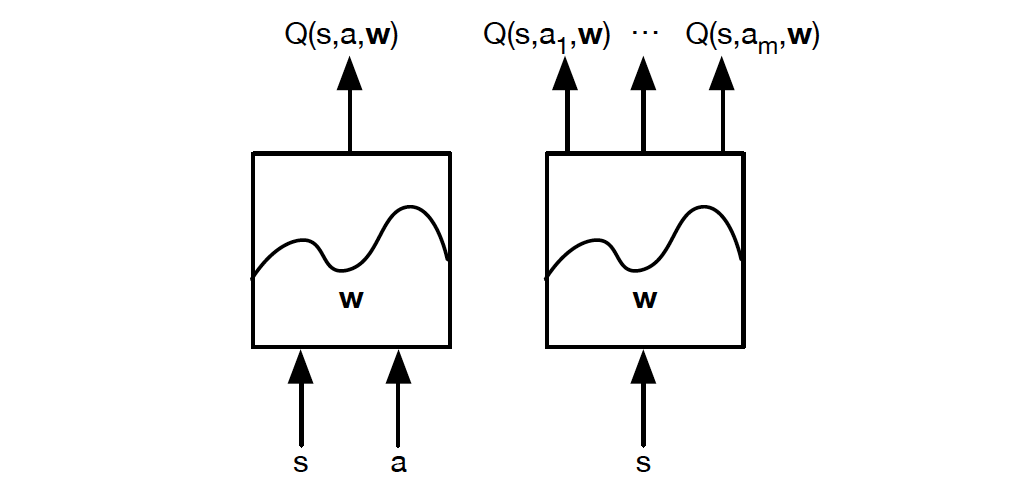
Lookup Table
Optimal Q-values should obey the Bellman equation Treat the right-hand side as a target
Minimize MSE loss by SGD:
-
Converges to Q* using table lookup representation (Q-table)
-
But diverges using neural networks due to
- Correlations between samples: to remove correlations, build dataset from agent’s own experience
- Non-stationary targets: to deal with non-stationarity, target parameters w’ are held fixed
Improvements to DQN
- Double DQN
- Prioritized replay
- Dueling network
Policy-based RL
- Search directly for the optimal policy
- This is the policy achieving maximum future reward
Policy Network
directly output the probability of actions without learning the Q-value function
- Guaranteed convergence to local minima
- High-dimensional (continuous) action spaces
- Stochastic policies (exploration/exploitation)
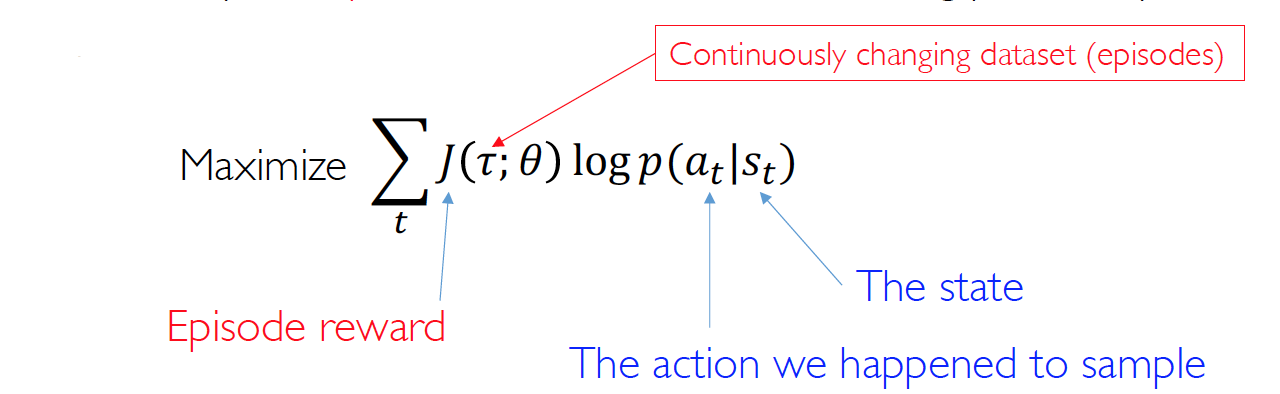
Policy Gradient(Reinforce)
policy gradients is exactly like supervised learning, except for:
- no correct label
- use fake label: sample action from policy
- training when an episode is finished
- scaled by the episode reward
- increase the log probability for actions that worked
Training protocol
For episode in range(max_episodes):
observation = env.reset()
While true (For each timestep) :
-
action = choose_action(observation)
-
observation_, reward, done = env.step(action)
-
store(observation, action, reward)
-
if done:
feed-forward policy network maximize
break
-
observation = observation_

Q-Learning vs. Policy Gradient
- Policy Gradient
- very general but suffer from high variance so requires a lot of samples
- Challenge: sample-efficiency
- Q-learning
- Does not always work but when it works, usually more sample-efficient
- Challenge: exploration
- Guarantees
- Policy Gradient: Converges to a local minima of , often good enough
- Q-learning: Zero guarantees since you are approximating the Bellman equation with a complicated function approximator