Attention Mechanism
在这里的注意力,是选择式注意力,在多个因素或者刺激物中选择,排除其他的干扰项。
Temporal Attention(时间)
-
one to one: MLP
-
many to one: Sentiment classification, sentent->sentiment
- one to many: Image Captioning, Image->Sentence
- many to many(heterogeneous): Machine Translation, sentence(en)->sentence(zh)
- many to many(homogeneous): Language Modeling, Sentence->Sentence
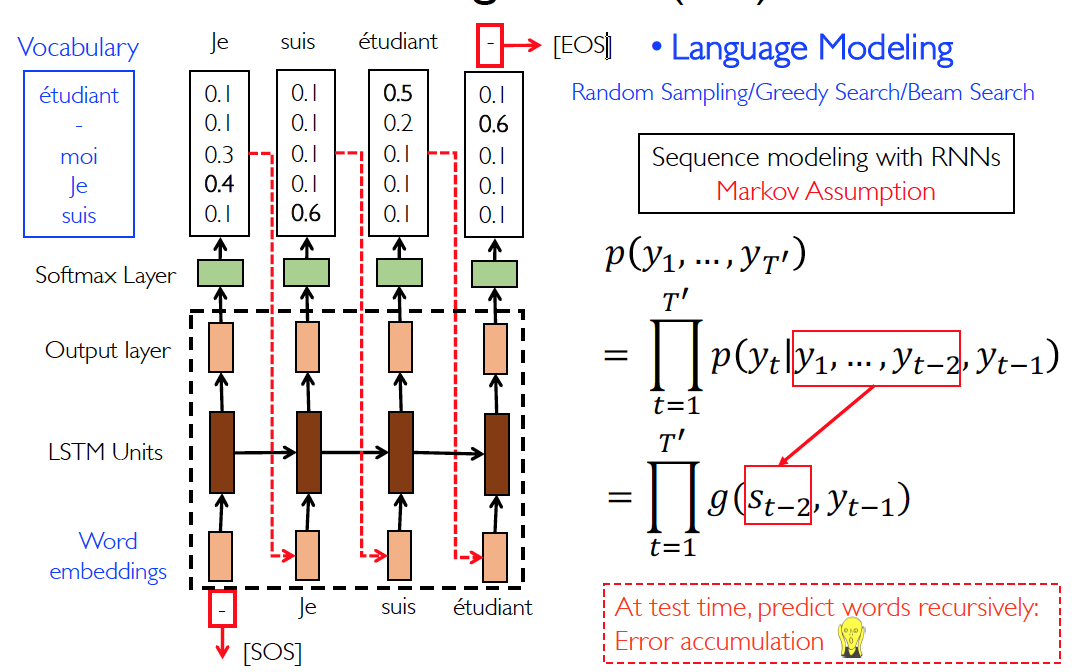
Autoregressive(AR)— Language Modeling
Seq2Seq with Attention—machine translation
Seq2Seq
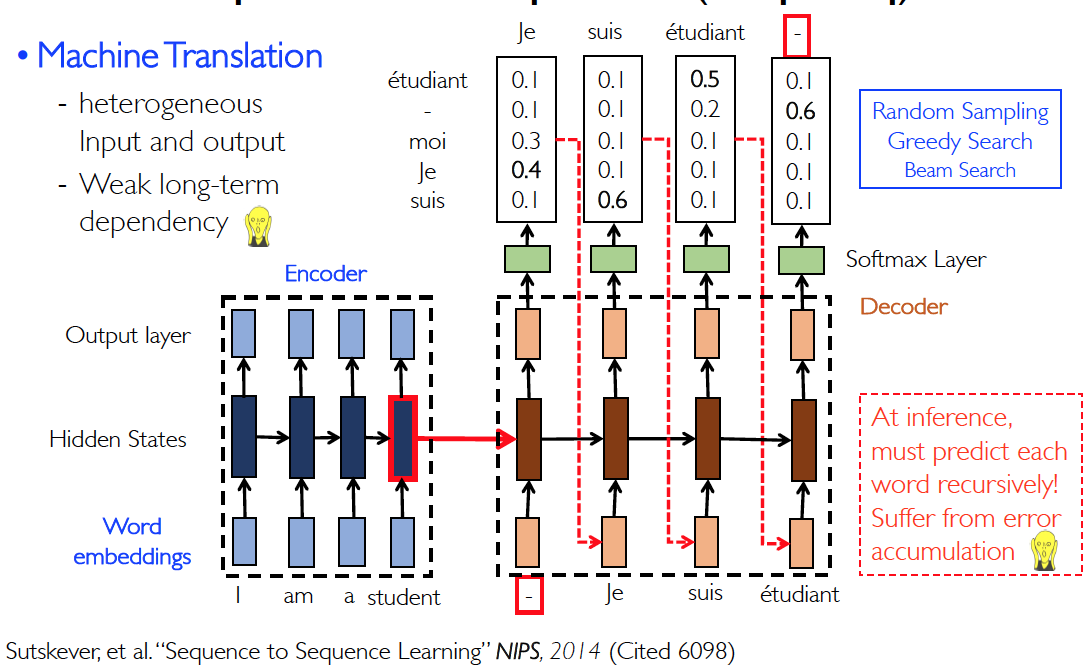
优点:
- 直接对建模
- 能够通过反向传播端到端训练
缺点:
- 将 source sequence 全部encode 到了一个hidden state c 中,使用c 去 decoding,这样会有信息丢失
- 梯度反向穿模的路径太长了,尽管有 LSTM forget,还是有梯度消失问题
- 翻译的语序可能在 source 和 target sequence 中不同
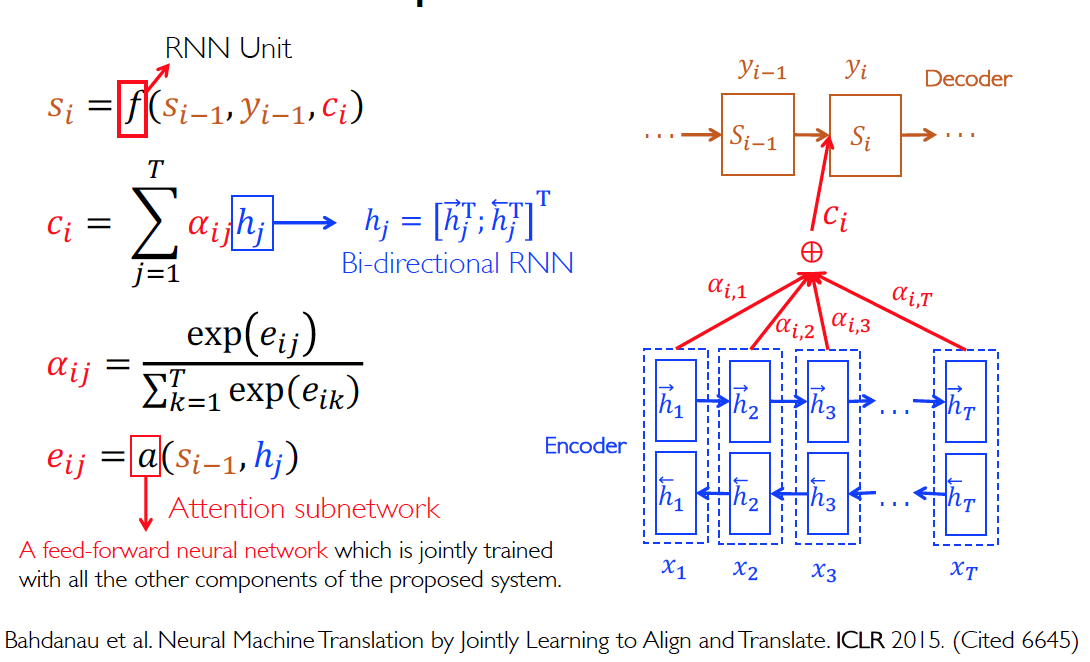
attention 机制可以解决梯度消失的问题,特别是在长句的翻译中
Global & Local Attention
Glocal Attention
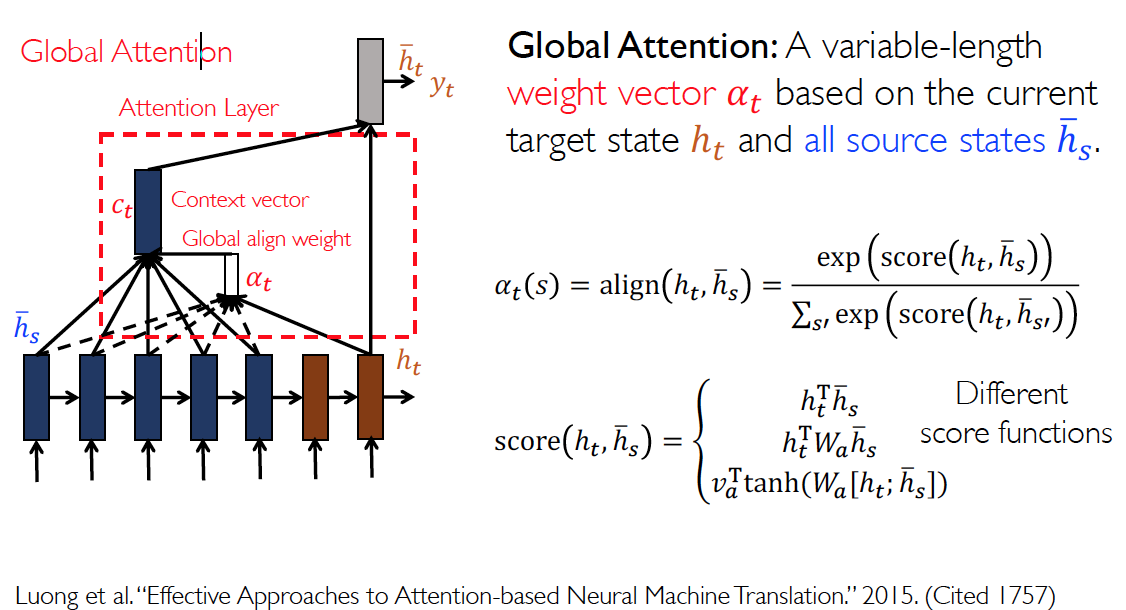
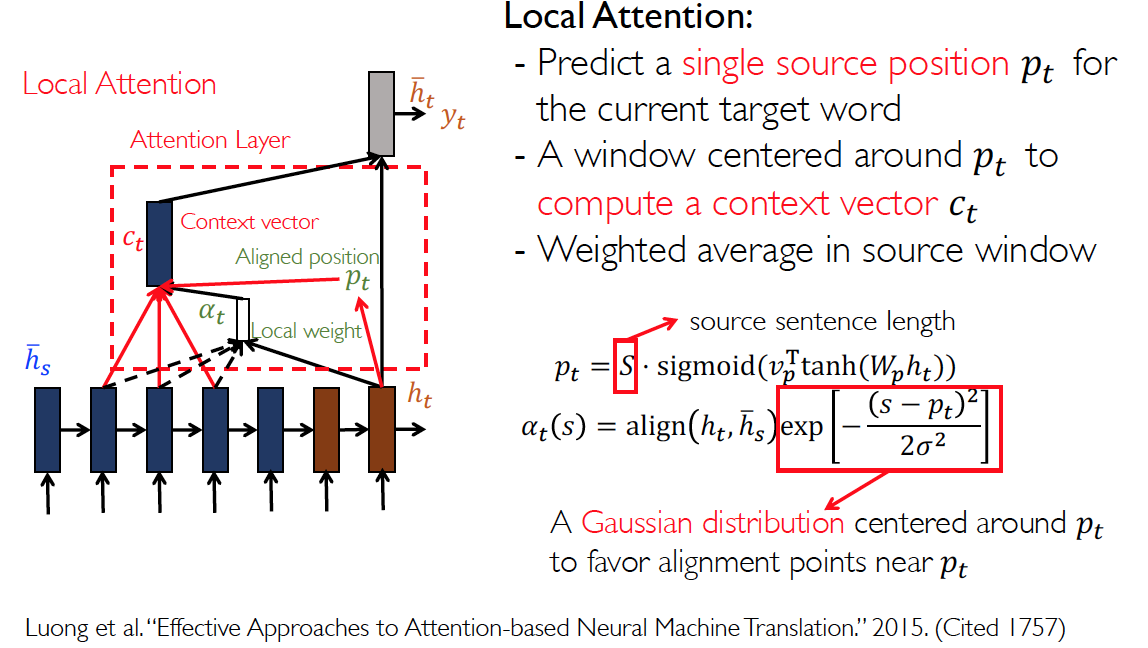
Local Attention
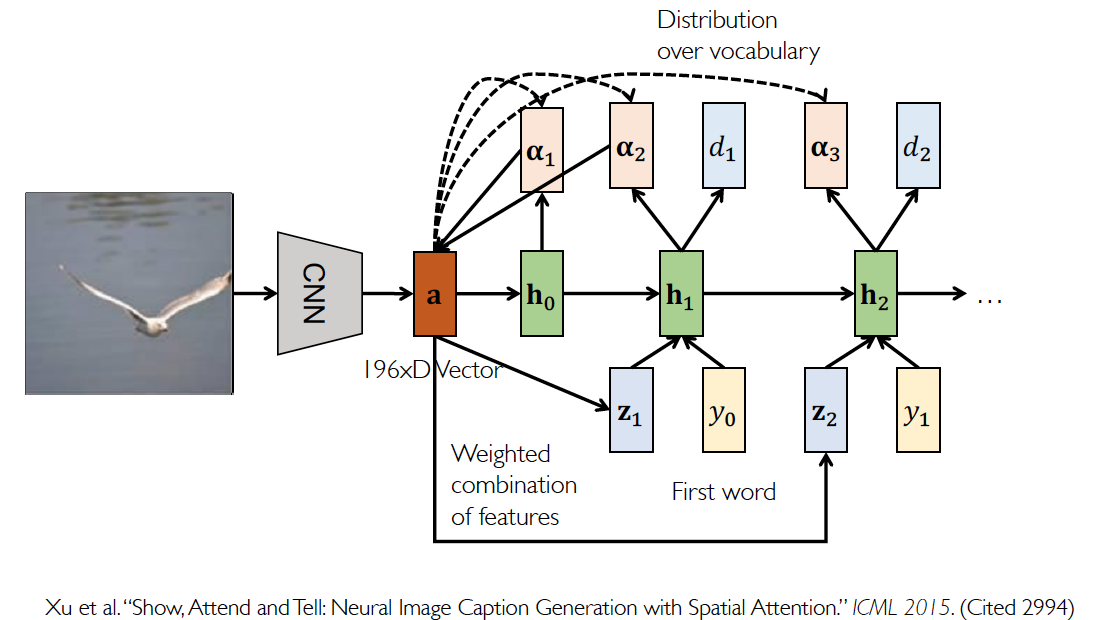
Spatial Attention(空间)
Image Captioning with Spatial Attention
Self Attention
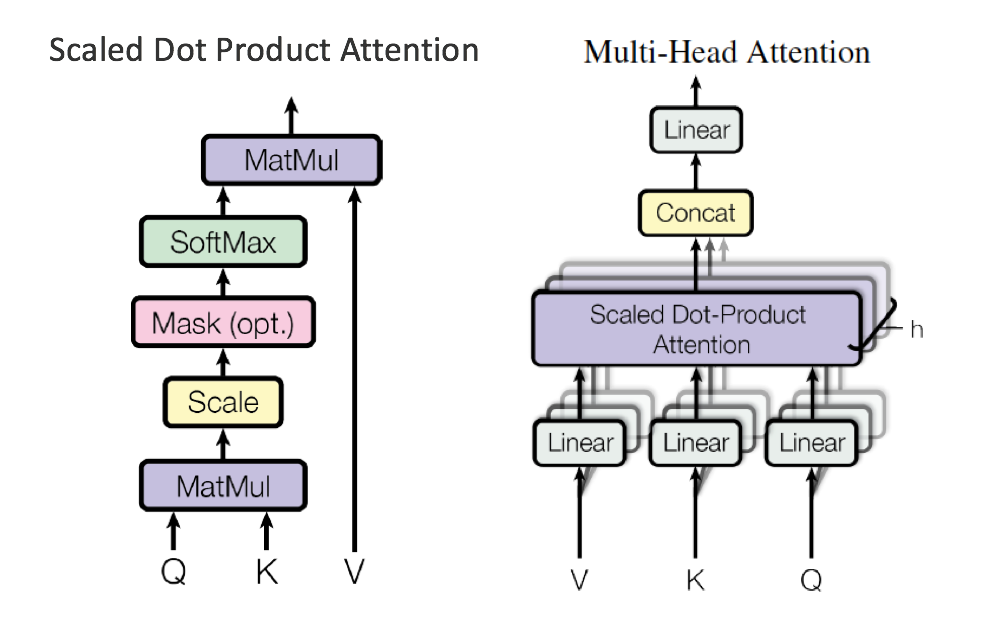
How to calculate attention?
given query vector q (target state) and key vector k (context states)
- Bilinear: , require parameters
- Dot Product: , increases as dimensions get larger
- Scaled Dot Product: , scale by size of the vector
- Self Attention:
- is dimension of Q(queries) and K(keys)
- Multi-Head Attention: , where
- Allows the model to jointly attend to information from different representation subspaces at different positions
- reduce dimension from to
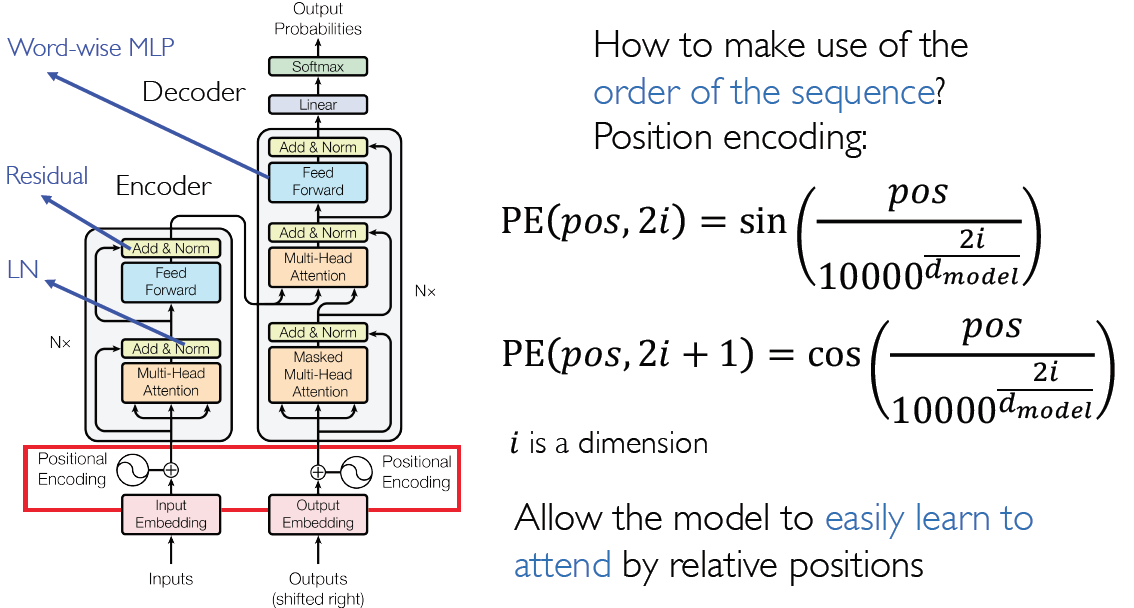
Transformer: Attention is All You Need
Positional Encoding
Convolutions and recurrence are not necessary for NMT
Compare Transformer with RNNs
RNN
- Strength: Powerful at modeling sequences
- Drawback: Their sequential nature makes it quite slow to train; Fail on large-scale language understanding tasks like translation
Transformer
- Strength: Process in parallel thus much faster to train
- Drawback: Fails on smaller and more structured language understanding tasks, or even simple algorithmic tasks such copying a string while RNNs perform well.
GPT & BERT
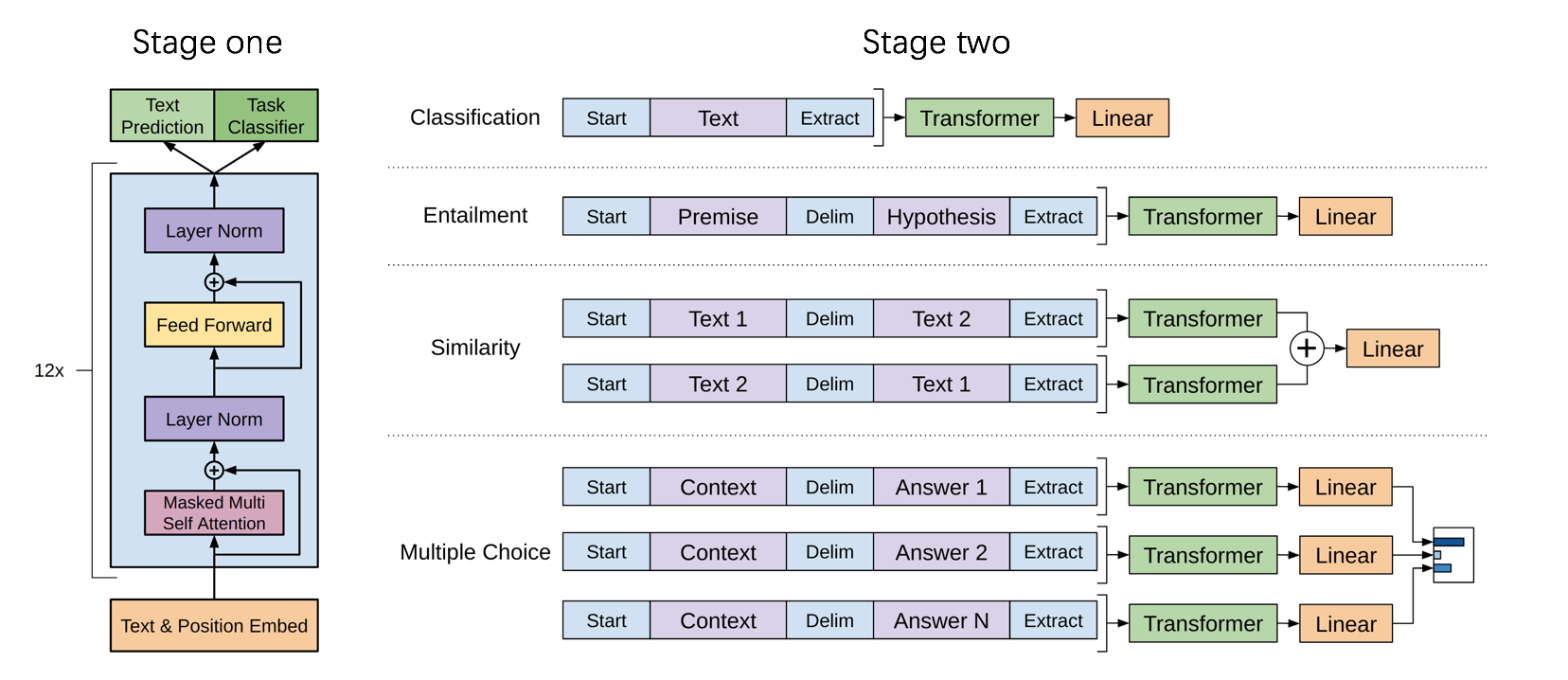
Generative Pre-Training(GPT)
Stage one: unsupervised pre-training
Given an unsupervised corpus of tokens , maximize likelihood:
The context vectors of tokens: where:
- U: The context vectors of tokens
- : The token embedding matrix
- : The position embedding matrix
Stage twe: supervised fine-tuning
Given a labeled dataset C, maximize the following objective: where:
- : The final transformer block’s activation
- : A linear output layer
BERT
Bidirectional Encoder Representations from Transformers (BERT)
Pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers
The pre-trained BERT representations can be fine-tuned with just one additional output layer
The input embeddings is the sum of the token embeddings, the segmentation embeddings and the position embeddings.