Recurrent Neural Network
-
Local dependency assumption: The sequential information of all previous timestamps can be encoded into one hidden representation. 2-order Markov assumption. Temporal receptive field: 2
-
Parameter Sharing assumption: If a feature is useful at time , then it should also be useful for all timestamp
但是实际上,两个假设在实际问题上都不会成立
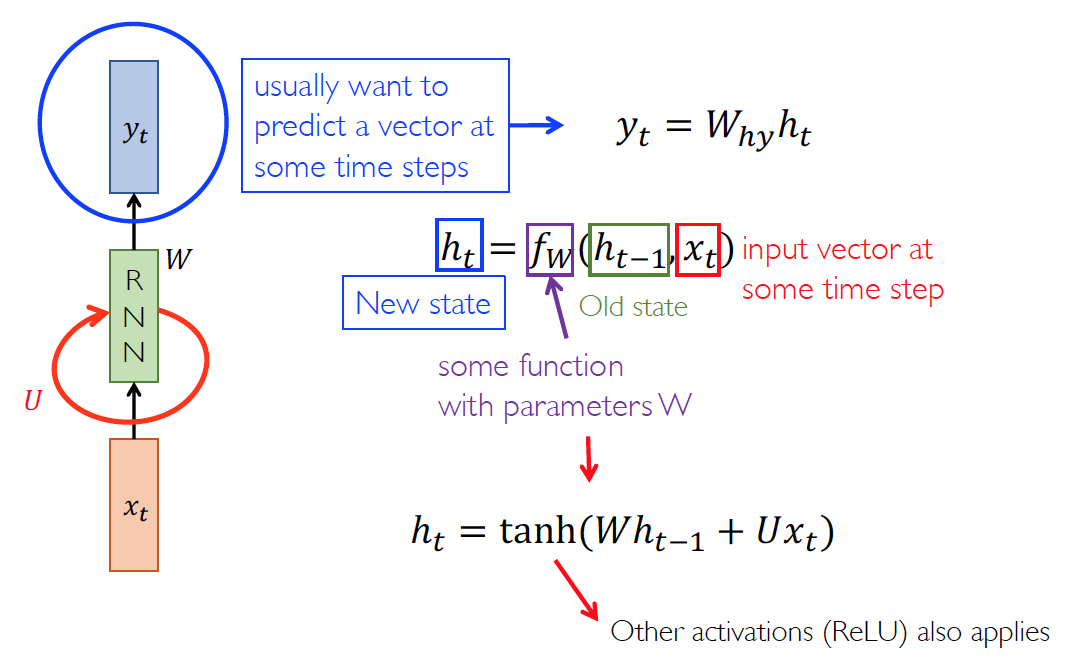
is used to encode the information from all past timesteps
Stationary assumption
we use the same parameters, W and U
Bidirectional RNN
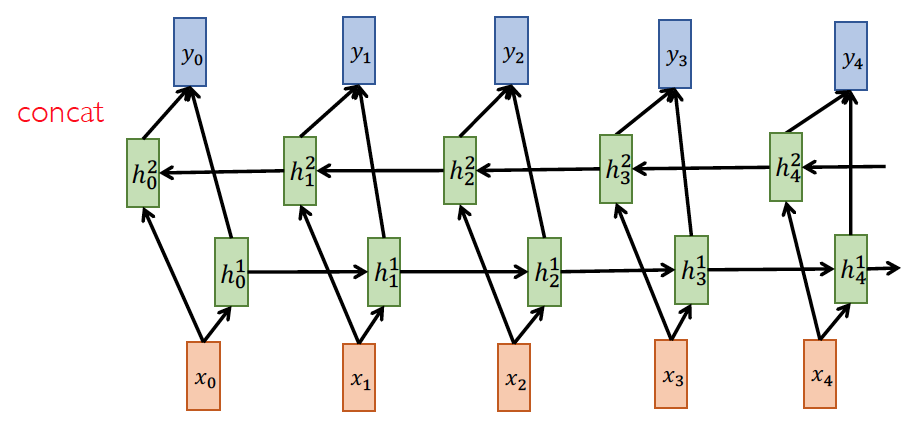
Deep RNN
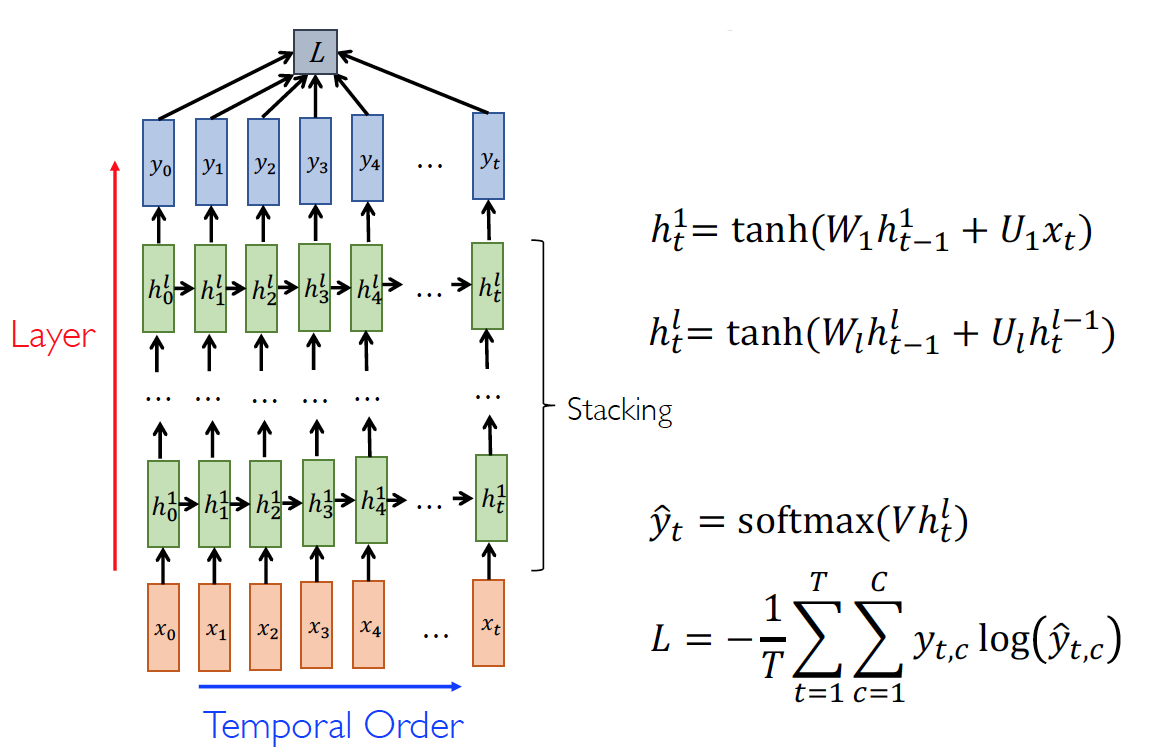
RNN for LanguageModel(LM)
- Advantages:
- RNNs can represent unbounded temporal dependencies
- RNNs encode histories of words into a fixed size hidden vector
- Parameter size does not grow with the length of dependencies
- Disadvantages:
- RNNs are hard to learn long range dependecies present in data
Back-Propagation Through Time(BPTT)
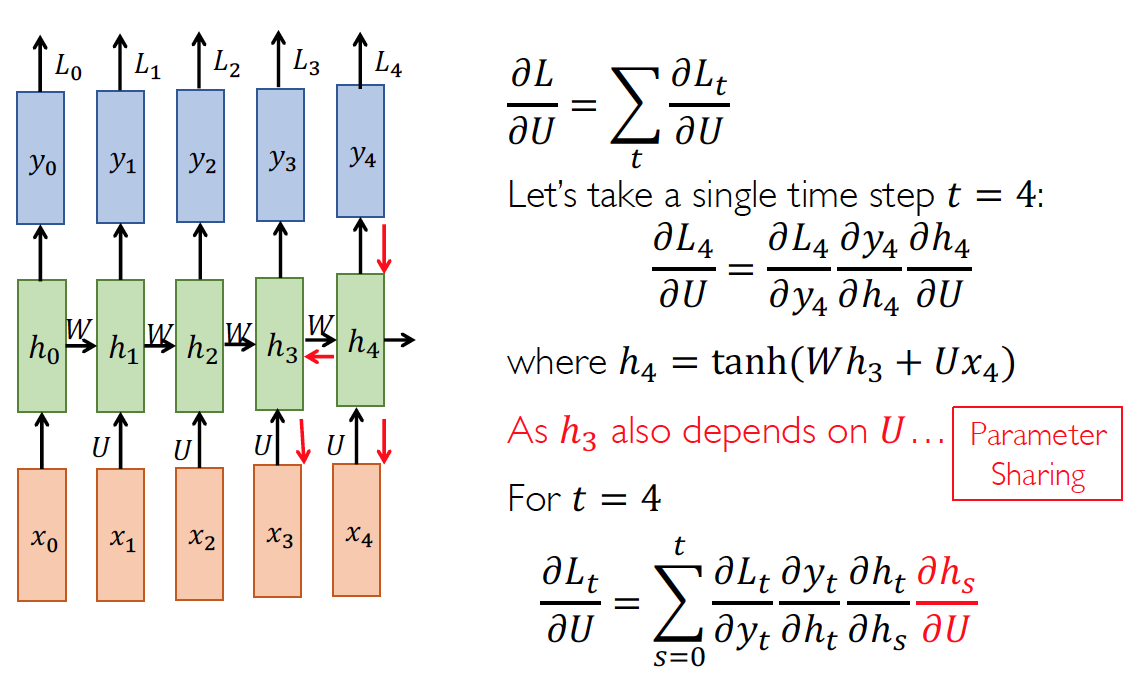 Gets longer and longer as the time gap (t-s) gets bigger!
Gets longer and longer as the time gap (t-s) gets bigger!
It has to learn a same transformation for all time steps
Truncated BPTT
原始的 RNN 计算 BPTT
-
Forward through entire sequence to compute loss
-
Backward through entire sequence to compute gradient
计算代价过高
Truncated BPTT:
Run forward and backward through chunks of the sequence instead of whole sequence
Truncation: carry hidden states forward in time forever, but only back-propagate for some smaller number of steps
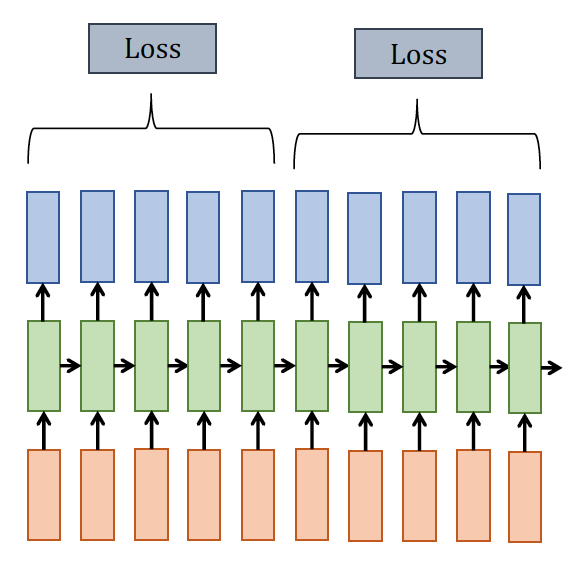
Learning Difficulty
Vanishing or Exploding gradient
where
- is the largest singular value of
- is the upper bound of
-
depends on activation function , e.g. $$\left \tanh ^{\prime}(x)\right \leq 1,\left \sigma^{\prime}(x)\right \leq \frac{1}{4}$$
Conclusion:
- RNNs are particularly unstable due to the repeated multiplication by the same weight matrix
- Gradient can be very small or very large quickly
Vanishing Gradient
为什么梯度消失是个问题?
- 不能学习到 long term dependencies,在语言模型中,在很远的词是不会影响到下一个词的预测的
对于梯度消失的小 trick:
- Orthogonal Initialization(正交初始化):
- 将参数 W 初始化为一个random orthogonal matrix (i.e. ), 所以一直乘不会改变norm ,因为
- Initialize W with small random entries, the
Long Short-Term Memory(LSTM)
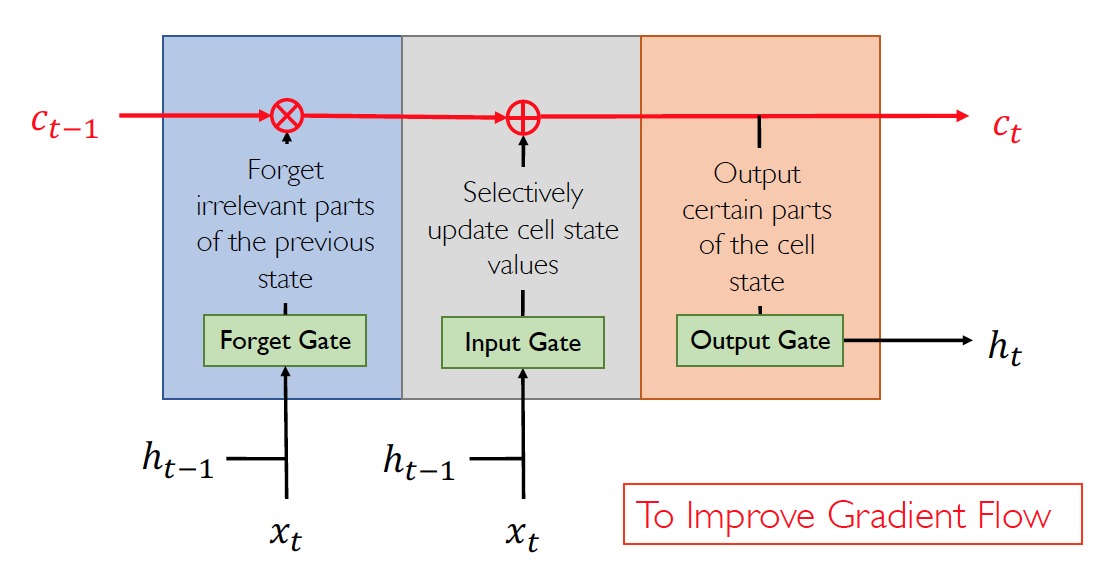
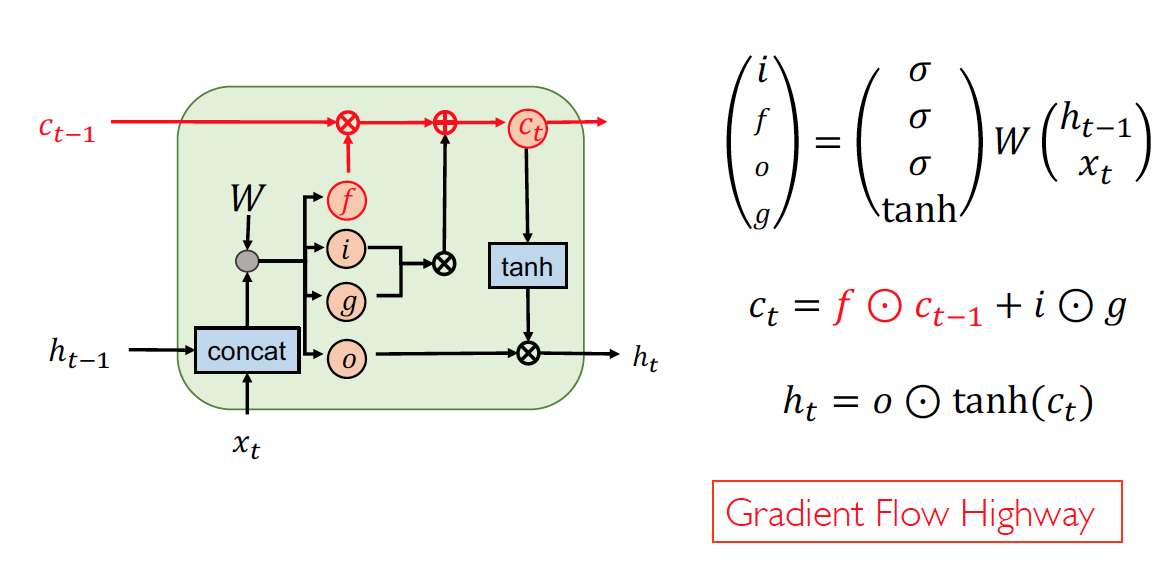
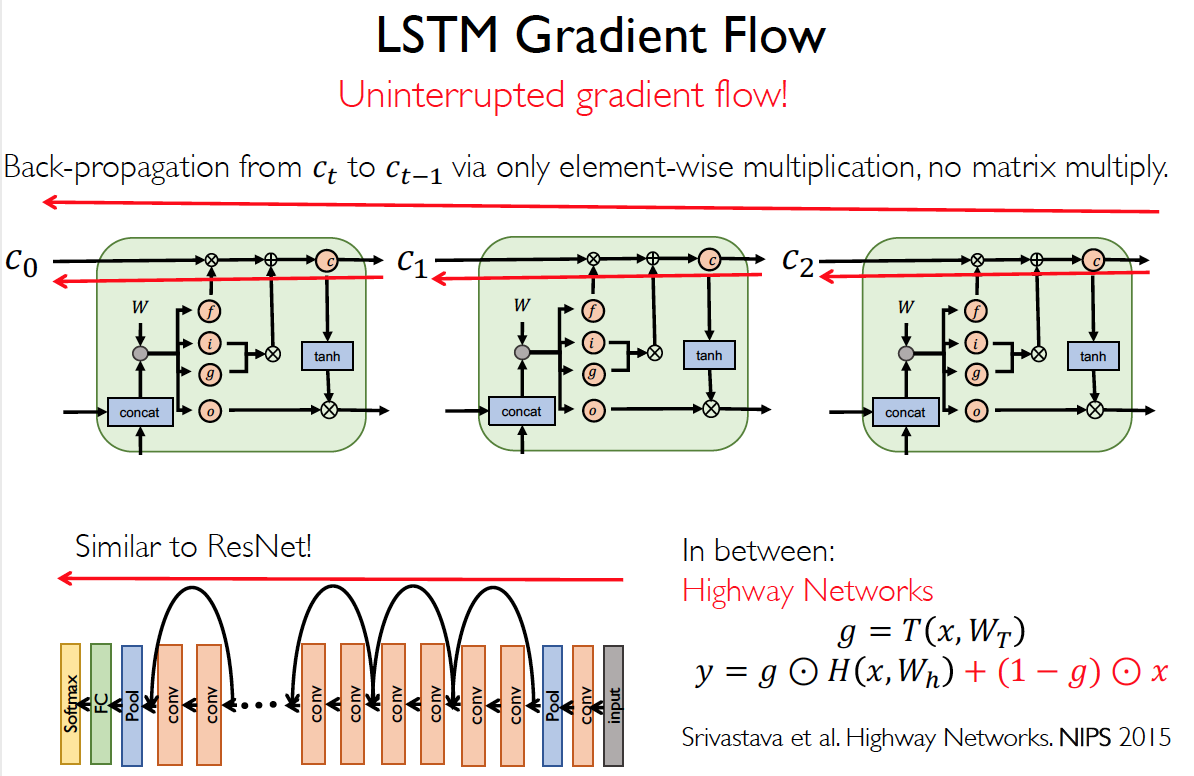 As long as forget gates are open (close to 1), gradients may pass into over long time gaps
As long as forget gates are open (close to 1), gradients may pass into over long time gaps
- Saturation of forget gates (=1) doesn’t stop gradient flow
- A beeter initialization of forget gate bias is e.g. 1
Add ‘peephole’ connections to the gates
-
Vanilla LSTM
-
Peephole LSTM
There is no significant performance improvement by peephole
None of the variants can improve upon the standard LSTM significantly
The forget gate and the output activation function (if cell state unbounded) to be its most critical components
Thus, we can couple the input and forget input () to work well->GRU
Gated Recurrent Unit(GRU)
GRU and LSTM yield similar accuracy, but GRU converges faster than LSTM

Exploding Gradient
L1 or L2 penalty on Recurrent Weight:
Regularize W to ensure that spectral radius of W not exceed I:
对于梯度爆炸的小 trick:
- Gradient Clipping: if ,
What if Batch Normalization?
batch normalization (makes the optimization landscape much easier to navigate and smooth the gradients!)
Problems when applied to RNNs:
- Saturation of forget gates(=1) doesn’t stop gradient flow
- Needs different statistics for different time-steps
- problematic if a test sequence longer than any training sequences
- Needs a large batch size
- problematic as RNNs usually have small batches (recurrent structures, e.g.LSTM, usually require larger memory usage )
Layer Normalization
- g(gain) and b(bias) are shared over all time-steps, the statistics are computed across each feature and are independent of batch sizes
- After multiplying inputs and state by weights but right before nonlinearity
Weight Normalization
- Lower computational complexity and less memory usage much faster then BN
- Prevents noise from the data without relying on training data
Practical Training Strategies
- Mismatch in training and inference
- curriculum learning
- scheduled sampling
- variational dropout