这篇论文是 CVPR Workshop 2019 的短文。本文学习到了一个攻击模型为图片打上 patch,可以欺骗 person detector,使攻击者不能被 person detector 检测出来



adversarial patch attack是学习一个 patch,放到一个物体上就可以骗过检测器或者分类器。而且这种欺骗是可以应用到真实世界中的,不只是在数字图片上做的修改。
本文的一个亮点是,他们的 target class 是有 intra-class variety,以前的论文都是说 stop-signs 的 patch,stop-signs 长的都很像,但是人的差别很大,有男人女人老人小孩,差异较大,人类这个种类的差异大。目标是试着骗过一个 person detector,使 detector 无法检测出来带有 patch 的人。图片上的人,左边就是成功地被检测出来,右边的人因为拿着 patch,躲过了 detector 的检测。所以一个入侵者能拿着 special design 的 patch 躲过 person detector 的检测。
本文的 pathch size 是 40cm 的正方形,他们攻击的目标模型是 yolov2

从 2013 年开始 bigio 就证明了对抗攻击在神经网络中的存在, 然后 Szegedy 用 L-BFGS 只微小地改变像素值 成功地生成了对抗样本,使模型输出错误的分类结果
 为了使在不同角度拍照的 pose 都有效,他们在一个大规模的数据集优化眼镜打印出来的图像。
为了使在不同角度拍照的 pose 都有效,他们在一个大规模的数据集优化眼镜打印出来的图像。

本文的工作和他们的区别在于他们考虑到了类之间的差异性,之前的例子如交通标志都是差不多的
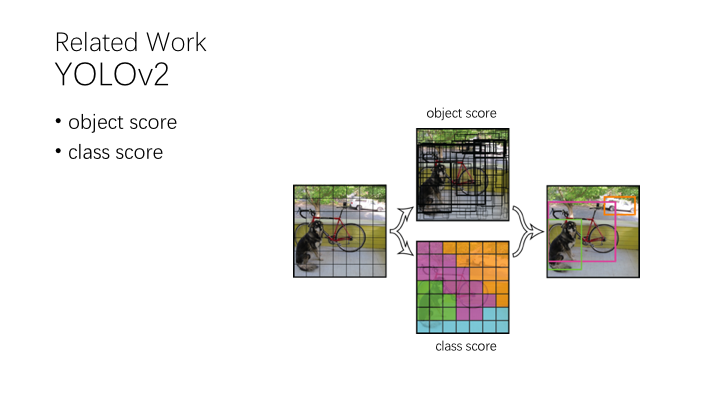
object score 包括一个 object 的概率
class score 属于哪个类别的概率

L_nps: 是表示在 patch 中的像素点能够被普通打印机打印出来的程度,因为 c_pirnt 是离散值,而 p_pathch 是浮点型的,在学习过程中尽量把 patch像素值靠近 能打印出来的像素值
L_tv: 这个 loss 是使patch 中的像素更 smooth 地颜色过度,而不是噪点图
L_obj 是图像中最高的 object score,就是说,这个 loss 降得越低,就越能藏住人
这三项 loss 用 alpha 和 beta 参数加权求和,用 adam 算法优化。
patch 中的像素值在开始时是随机初始化的

第一种,倾向于把种类-人转换成其他类别
a 和 b 用 class 和 object score 的乘积作为 LOSS function,a 图中学习到的 patch 像一个泰迪熊,检测器识别成泰迪熊的概率超过了识别成人类的概率,但是因为 patch 像其他类,这种 patch 在其他没有这个类别的数据集训练出来的模型上 transferable 不好
c 是使用我们的刚才设置的目标函数,就没有刚才的问题,不像一个什么物体

challenge:
1.人和人差距很大,不像交通标示,如 stop sign 是八边形红色
2.人可能出现在很多场景中,而 stop sign 基本都是在路边
3.人相对于相机的朝向也有影响
4.在人上没有固定贴 patch 的地方,stop sign 可以很容易计算贴到哪里
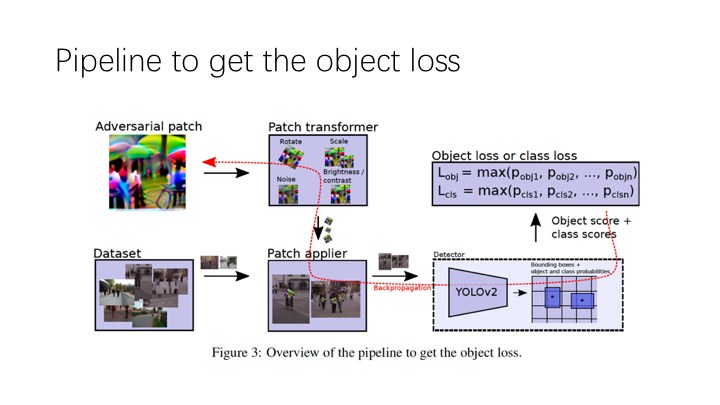

在现实世界中,需要把 patch 打印出来,然后用 video camera 记录下俩,所以有很多影响因素,比如光纤,patch 的 rotation,patch 的 size,camera 可能会轻微地在 patch 上加上 noise 或者虚化,还有摄影角度。为了尽量考虑到这些因素,他们做了一些随机的 transformation 在 patch 上。
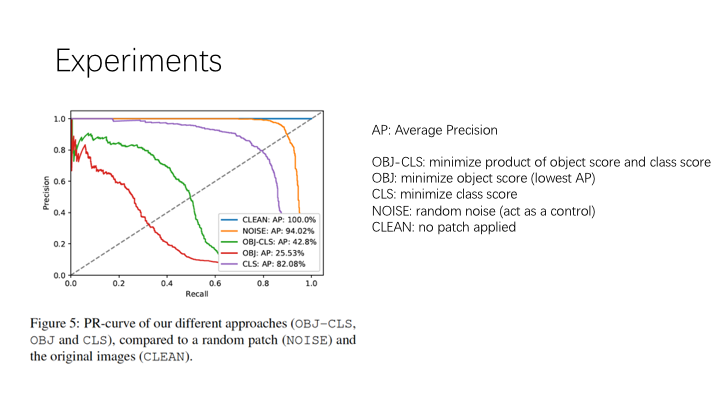
在 digital 的数据集上测试,也在 real-world 中测试了。真实世界的结果详见 youtube
在 Inria 测试集上用 training 一样的过程把 patch 贴上,包括一些随机的 transformation

第一排是没有 patch 的,第二排是有一个 random patch,第三排是根据 OBJ 生成的最好的 patch,在大多数情况下是可以用 patch 将人从 detector 中隐藏的。
也有失败的案例,第四列,patch 没有在人的中间,因为在训练过程中,patch 只会放在bounding box的中间。
